

6. Java - 集合
集合
每天学习新知识,每天进步一点点。
前面文章说过,数组可以保存多个对象,但在某些情况下,无法确定到底需要保存多少个对象,此时数组不再适用,因为数组的长度不可变。为了保存数目不确定的对象,Java中提供了一系列特殊类,统称为
集合,集合可以存储任意类型的对象,并且长度可变。本文将针对Java中的集合进行详细介绍。
1. 集合概述
集合就像一个容器,专门用来存储Java对象(实际上是对象的引用,但习惯上成为对象),这些对象可以是任意类型,并且长度可变。集合类都位于
java.util包下,在使用时,要注意导包的问题,否则会出现异常。
集合按照存储结构可以分为两大类,即单列集合Collection和双列集合Map。这两种集合的特点具体如下:
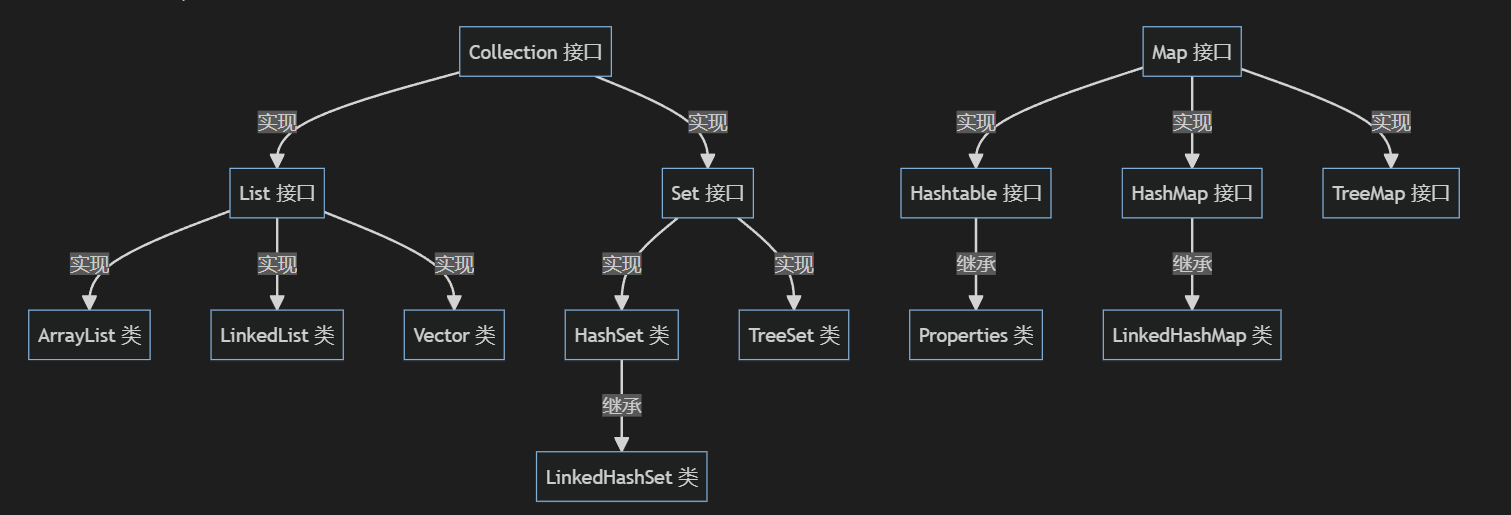
Collection:单列集合的根接口,用于存储一系列符合规则的元素。Collection集合有两个重要的子接口,分别是List和Set。其中List的特点是元素有序,可重复,而Set的特点是元素无序,不可重复。List接口的主要实现类有ArrayList和LinkedList,Set接口的主要实现类有HashSet和TreeSet。Map:双列集合的根接口,用于存储一系列键值对映射关系。Map集合中每个元素都包含一堆键值,并且Key是唯一的,在使用Map集合时可以通过指定的Key找到对应的Value。Map接口有三个主要的实现类,分别是HashMap和TreeMap。
表1-1 集合体系核心架构图
2. Collection 接口
Collection接口是单列集合的根接口,它定义了一些通用的方法,包括add()、remove()、clear()、isEmpty()、size()等。如表2-1所示。
表2-1 Collection 接口的主要方法
| 方法声明 | 功能描述 |
|---|---|
| boolean add(Object o) | 添加元素到集合中 |
| boolean addAll(Collection c) | 将指定集合c中的所有元素添加到当前集合中 |
| void clear() | 清空集合中的所有元素 |
| boolean remove(Object o) | 从集合中删除指定元素 |
| boolean removeAll(Collection c) | 从集合中删除指定集合c中的所有元素 |
| boolean isEmpty() | 判断集合是否为空 |
| boolean retainAll(Collection c) | 保留当前集合中与指定集合c中相同的元素 |
| boolean contains(Object o) | 判断集合中是否包含指定元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含指定集合c中的所有元素 |
| int size() | 返回集合中元素的个数 |
| Iterator iterator() | 返回一个迭代器,用于遍历集合中的元素 |
| Stream | 将集合源转换为有序元素的流对象,用于对集合中的元素进行操作 |
tip:Collection集合的主要方法都来自JavaAPI文档,可以通过查询API文档来了解每个方法的具体功能。现在列出来,是为了方便后面学习使用。
3. List 接口
3.1 List 接口简介
List接口是单列集合的主要接口,在List集合中允许出现重复的元素,所有的元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的指定元素。另一个特点就是元素有序,即元素的存入顺序和取出顺序一致。它继承自Collection接口,并添加了一些额外的方法,如表3-1所示。
表3-1 List 接口的主要方法
| 方法声明 | 功能描述 |
|---|---|
| void add(int index, Object element) | 在指定位置添加元素 |
| boolean addAll(int index, Collection c) | 将指定集合c中的所有元素添加到当前集合中,从指定位置开始 |
| Object get(int index) | 返回指定位置的元素 |
| int indexOf(Object o) | 返回指定元素在集合中首次出现的索引 |
| int lastIndexOf(Object o) | 返回指定元素在集合中的最后出现的索引 |
| Object remove(int index) | 从指定位置删除元素 |
| Object set(int index, Object element) | 将索引index处的元素替换为element元素,并将替换后的元素返回 |
| List subList(int fromIndex, int toIndex) | 返回从索引fromIndex(包括)到索引toIndex(不包括)处所有元素集合组成的子集合 |
| Object[] toArray() | 返回集合中所有元素组成的数组 |
| default void sort(Comparator<? super E> c) | 根据指定得比较器规则对集合元素进行排序 |
tip:sort(Comparator<? super E> c)方法是Java8引入的新方法,用于对集合元素进行排序。该方法参数是一个接口类型的比较器Comparator,可以通过Lambda表达式传入函数式接口作为参数,指定集合元素的排序规则。
3.2 ArrayList 类
ArrayList内部封装了一个长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会自动扩容,以便容纳更多的元素。因此可将ArrayList集合看作是一个长度可变的数组。正是由于数据存储结构是数组形式,在增加或删除指定位置元素时,都会创建新数组,效率比较低,所以不适合做大量的增删操作。但是这种数组结构允许程序通过索引方式访问元素,因此遍历和查找元素十分高效。
ArrayList集合中的大部分方法都是从接口Collection和List中继承而来,接下来通过一个案例学习如何使用ArrayList集合的方法存取元素。如例:
例3-1 Demo1.java
import java.util.ArrayList;
public class Demo1{
public static void main(String[] args){
//创建ArrayList集合
ArrayList arr = new ArrayList();
arr.add("十");
arr.add("一");
arr.add("月");
arr.add("的");
arr.add("早");
arr.add("晨");
System.out.println("集合的长度为:" + arr.size());
System.out.println("集合中第三个元素为:" + arr.get(2));
}
}
输出结果:
集合的长度为:6
集合中第三个元素为:月
例3-1中,首先通过new ArrayList()创建了一个ArrayList集合对象,然后通过add()方法添加了一些元素到集合中,最后通过size()方法获取了集合的长度,以及通过get()方法获取了集合中第三个元素。从输出结构可以看出,索引位置为2的元素是集合中的第三个元素,这说明集合和数组一样,索引取值都是从0开始,最后一个索引是size-1,注意取值时索引不要越界。
3.3 LinkedList 集合
ArrayList集合在查询元素时速度很快,但是在增删元素时效率低下,为了解决这个问题,可以使用List的另一个实现类LinkedList。该集合内部包含有两个Node类型的first和last属性维护一个双向链接,链表中的每一个元素都使用引用的方式来记住它的前后元素,从而可以将所有元素彼此连接起来。当增删元素时,只需要修改元素间的引用关系即可。因此,LinkedList集合在增删元素时效率高,但是在查询元素时速度慢。
LinkedList集合中的大部分方法都是从接口Collection和List中继承而来,还专门针对元素的增删操作定义了一些特有的方法,如表表3-2所示。
表3-2 LinkedList 集合的主要方法
| 方法声明 | 功能描述 |
|---|---|
| void add(int index, E element) | 在指定位置添加元素 |
| void addFirst(Object o) | 在集合开头添加元素 |
| void addLast(Object o) | 在集合结尾添加元素 |
| Object getFirst() | 返回集合第一个元素 |
| Object getLast() | 返回集合最后一个元素 |
| Object removeFirst() | 移除并返回集合的第一个元素 |
| Object removeLast() | 移除并返回集合的最后一个元素 |
| boolean offer(Object o) | 把元素添加到集合末尾,如果空间不足,则抛出异常 |
| boolean offerFirst(Object o) | 把元素添加到集合开头,如果空间不足,则抛出异常 |
| boolean offerLast(Object o) | 把元素添加到集合末尾,如果空间不足,则抛出异常 |
| Object peek() | 获取集合的第一个元素 |
| Object peekFirst() | 获取集合的第一个元素 |
| Object peekLast() | 获取集合的最后一个元素 |
| Object poll() | 移除并获取集合的第一个元素 |
| Object pollFirst() | 移除并获取集合的第一个元素 |
| Object pollLast() | 移除并获取集合的最后一个元素 |
| void push(Object o) | 将元素添加到集合开头 |
| Object pop() | 移除并返回集合的第一个元素 |
接下来通过一个案例来学习LinkedList集合的常见使用方法。如例:
例3-2 Demo2.java
import java.util.LinkedList;
public class Demo2{
public static void main(String[] args){
LinkedList list = new LinkedList();
//1. 添加元素
list.add("一");
list.add("月");
list.add("的");
//输出集合中的元素
System.out.println(list);
//向集合尾部追加元素
// 1. 使用addLast添加元素到末尾
// list.addLast("晨");
// 2. 使用offer 返回是否添加成功
// list.offer("晨");
//3. 使用offerLast 返回是否添加成功
list.offerLast("晨");
// 向集合头部追加元素
// 1.使用addFirst添加元素到开头
// list.addFirst("十");
// 2. 使用push
// list.push("十");
// 3. 使用offerFirst 返回是否添加成功
list.offerFirst("十");
//向集合指定位置追加元素
list.add(4,"早");
//输出集合中的元素
System.out.println(list);
//2. 获取元素
//获取集合中的第一个元素
// 1. 使用peek()
Object o = list.peek();
// 2. 使用peekFitst()
Object o1 = list.peekFirst();
// 3. 使用 getFirst()
Object o2 = list.getFirst();
//输出集合中的元素
System.out.println("peek:" + o + "\npeekFirst:" + o1 + "\ngetFirst:" + o2);
System.out.println(list);
//3. 删除元素
//删除集合第一个元素
// 1. removeFirst 会返回删除的元素
//Object o3 = list.removeFirst();
// 2. poll 会返回删除的元素
// Object o3 = list.poll();
// 3. pollFirst 会返回删除的元素
// Object o3 = list.pollFirst();
// 4. pop 会返回删除的元素
Object o3 = list.pop();
//删除集合最后一个元素
// 1. removeLast 会返回删除的元素
//Object o4 = list.removeLast();
// 2. pollLast 会返回删除的元素
Object o4 = list.pollLast();
//输出集合中的元素
System.out.println("删除的第一个元素:" + o3 + "\n删除的最后一个元素:" + o4);
System.out.println(list);
}
}
输出结果:
[一, 月, 的]
[十, 一, 月, 的, 早, 晨]
peek:十
peekFirst:十
getFirst:十
[十, 一, 月, 的, 早, 晨]
删除的第一个元素:十
删除的最后一个元素:晨
[一, 月, 的, 早]
tip:LinkedList在Java中提供了多种方法来实现相似的功能,这是为了提供灵活性、遵循不同接口的约定并确保与Java集合框架的兼容性。LinkedList实现了List和Deque接口,这导致了一些功能重叠。例如,add(E e)和offer(E e)都会在列表的末尾添加元素,但offer方法来自Queue接口,它的返回类型是boolean,以指示添加是否成功,而add方法则没有返回值或在失败时抛出异常。此外,通过提供多种方法来执行相同的操作,可以让程序员根据具体的语境选择最适合他们需求的API。
4. Collection 集合遍历
4.1 Iterator(迭代器) 遍历集合
Iterator接口是Java集合框架中用于遍历集合元素的接口,它提供了一种统一的方法来访问集合中的元素,而无需知道集合底层的结构。
Iterator接口的主要方法有:
-
hasNext():方法用于判断集合中是否还有下一个元素 -
next()方法用于获取下一个元素 -
remove()方法用于删除当前迭代器指向的元素
接下来通过一个案例来演示如何使用Iterator遍历集合。如例:
例4-1 Demo3.java
import java.util.ArrayList;
import java.util.Iterator;
public class Demo3 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
// 向集合中添加元素
list.add("十");
list.add("一");
list.add("月");
list.add("的");
list.add("早");
list.add("晨");
list.add("。");
list.add("你好");
Iterator iterator = list.iterator();
// 判断集合中是否还有下一个元素
while (iterator.hasNext()) {
// 获取下一个元素
Object o = iterator.next();
if ("你好".equals(o)) {
// 使用remove删除当前迭代器指向的元素
iterator.remove(); // 删除元素"你好"
System.out.println("\n已删除元素: " + o);
} else {
System.out.print(o); // 打印元素
}
}
// 打印删除后的集合
System.out.println("\n删除后的集合: " + list);
}
}
输出结果:
十一月的早晨。
已删除元素: 你好
删除后的集合: [十, 一, 月, 的, 早, 晨, 。]
例4-1中,首先创建了一个ArrayList集合,并向其中添加了一些元素。然后通过iterator()方法获取了一个Iterator对象,并通过hasNext()和next()方法遍历集合中的元素,并在遍历到"你好"时使用remove()方法删除了该元素。最后,打印出删除后的集合。Iterator迭代器对象在遍历集合时,内部采用指针的方式跟踪集合中的元素。在调用next()之前,迭代器的索引位于第一个元素之前,不指向任何元素。当第一次调用后,索引会向后移动一位,指向第一个元素并将该元素返回。当调用next()方法时,迭代器的索引会向后移动一位,指向下一个元素并将该元素返回。以此类推,直至hasNext()方法返回false,表示遍历结束。
tip:在使用Iterator迭代器进行迭代时,如果调用了集合对象的remove()方法去删除元素,会出现ConcurrentModificationException异常。
将iterator.remove(); 修改为 list.remove(o),就会抛出异常,示例:
十一月的早晨。
已删除元素: 你好
Exception in thread "main" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)
at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967)
at Demo3.main(Demo3.java:24)
这是因为Iterator迭代器只能在遍历集合时使用,在遍历过程中,如果我们使用集合的remove()方法删除元素,集合的结构就发生变化,导致Iterator迭代器预期的迭代次数发生改变,结果不准确。为了解决这个问题,有两种解决方案:
- 如果业务逻辑上我们只想删除那一个元素,则可以
remove()完成后,跟上break即可。因为我们只需要找到这个元素删除,删除完成跳出循环不在迭代即可,示例:
while (iterator.hasNext()) {
Object o = iterator.next();
if ("你好".equals(o)) {
list.remove(o); // 删除元素"你好"
System.out.println("\n已删除元素: " + o);
break; // 跳出循环
} else {
System.out.print(o); // 打印元素
}
}
- 不使用集合的
remove()方法,而是使用Iterator的remove()方法即可解决这个问题,案例中使用的就是这个方法,所以不再给出代码。
4.2 ForEach 遍历集合
虽然
Iterator可以用来遍历,但写法上太过繁琐,为了简化书写,Java 5 开始引入了新方法forEach循环。它是一种更加简洁的for循环,它可以用来遍历集合中的元素,并对每个元素执行某种操作。
其语法如下:
for(容器中元素类型 临时变量:容器变量){
//执行语句
}
从上面格式可以看出,与for循环相比,forEach循环的格式更加简洁,不需要获得容器长度,也不需要根据索引访问元素,会自动遍历容器中每个元素,只需要指定容器变量即可。
接下来通过案例来学习foreach循环方法的使用,如例:
例4-2 Demo4.java
import java.util.ArrayList;
public class Demo4{
public static void main(String[] args){
ArrayList list = new ArrayList();
// 向集合中添加元素
list.add("十");
list.add("一");
list.add("月");
list.add("的");
list.add("早");
list.add("晨");
list.add("。");
//使用foreach循环遍历元素
for(Object o : list){
System.out.print(o);
}
}
}
输出结果:
十一月的早晨。
tip:foreach循环虽然用起来很方便,但是也具有局限性,当使用foreach循环遍历集合时,只能对集合中的元素进行遍历,不能对集合本身元素进行修改。
4.3 JDK 8 的 forEach 遍历集合
JDK 8中,根据
Lambda表达式特性,还增加了个一个forEach(Consumer action)方法来遍历集合,该方法的参数是一个函数式接口。
接下来通过一个案例来演示如何使用forEach方法遍历集合。如例:
例4-3 Demo5.java
import java.util.ArrayList;
public class Demo5{
public static void main(String[] args){
ArrayList list = new ArrayList();
// 向集合中添加元素
list.add("十");
list.add("一");
list.add("月");
list.add("的");
list.add("早");
list.add("晨");
list.add("。");
//使用JDK 8 提供的forEach方法遍历
list.forEach(o -> System.out.print(o));
}
}
输出
十一月的早晨。
JDK 8中除了针对所有集合类型对象增加了forEach()方法,还针对Iterator迭代器对象增加了一个forEachRemaining(Consumer action)方法,该方法与forEach()方法的功能相同,但它可以遍历剩余的元素,而不是遍历整个集合。
如例:
例4-4 Demo6.java
import java.util.ArrayList;
import java.util.Iterator;
public class Demo6{
public static void main(String[] args){
ArrayList list = new ArrayList();
// 向集合中添加元素
list.add("十");
list.add("一");
list.add("月");
list.add("的");
list.add("早");
list.add("晨");
list.add("。");
//获取Iterator对象
Iterator iterator = list.iterator();
//1. 使用JDK 8 提供的forEachRemaining方法遍历整个集合
// iterator.forEachRemaining(o -> System.out.print(o));
//2. 使用Iterator迭代前两个,剩余的使用forEachRemaining遍历输出
int i = 0;
while(iterator.hasNext()){
if(i++ == 2){
break;
}
Object o = iterator.next();
System.out.println("Iterator迭代的元素:" + o);
}
iterator.forEachRemaining(o -> System.out.println("forEach遍历剩余:" + o));
}
}
输出结果:
Iterator迭代的元素:十
Iterator迭代的元素:一
forEach遍历剩余:月
forEach遍历剩余:的
forEach遍历剩余:早
forEach遍历剩余:晨
forEach遍历剩余:。
tip:forEach()方法和forEachRemaining()方法都可以用来遍历集合,但是它们的区别在于,forEach()方法遍历整个集合,而forEachRemaining()方法可以遍历剩余的元素。
5. Set 接口
5.1 Set 接口简介
Set接口和List接口一样,同样继承自Collection接口,方法基本一致,并没有扩充新的方法,只是比Collection方法更加严格。与List接口不同,Set接口要求元素不能重复,而且没有顺序。Set接口有两个主要的实现类,分别是HashSet和TreeSet。其中,HashSet是根据对象的哈希值来确定元素存储在集合中的位置,因此具有良好的存取和查找性能。TreeSet是以二叉树来存取元素,可以实现对集合中的元素进行排序。
5.2 HashSet 集合
HashSet是Set接口的一个实现类,它所存储的元素都是无序、不可重复的。当向HashSet集合中添加元素时,首先会调用该元素的hashCode()方法来确定元素的存储位置,在调用元素对象的equals()方法确保该位置没有重复元素。
接下来通过案例来学习HashSet集合的使用,如例:
例5-1 Demo7.java
import java.util.HashSet;
public class Demo7{
public static void main(String [] args){
HashSet set = new HashSet(); //创建HashSet对象
set.add("十一月");
set.add("的早晨");
set.add("Hello");
set.add("World");
set.add("Hello"); //向集合中添加重复元素
//使用forEach遍历元素
set.forEach(o -> System.out.print(o));
}
}
输出
Hello的早晨十一月World
例5-1中,创建了一个HashSet集合,并向其中添加了一些元素,其中包含重复元素。然后使用forEach()方法遍历集合中的元素,并输出。从打印结果可以看出,取出元素的顺序与添加的顺序并不一致,并且重复存入的元素也被去除了,只出现了一次。
HashSet集合之所以能确保不出现重复的元素,是因为在存入元素前,先调用存入当前元素的hashCode()方法获得对象的哈希值,然后根据对象的哈希值计算存储位置,如果该位置上没有元素,则存入,如果有,则会再调用equals()方法让当前存入的元素依次与该位置上的元素进行比较,如果返回的结果为false,则说明该位置上没有重复元素,则存入,如果返回的结果为true,则说明该位置上有重复元素,则不存入。
根据上面的分析,我们不难看出,当向集合中存入元素时,为了确保HashSet正常工作,需要在存入对象前,重写Object类的hashCode()方法和equals()方法,以保证对象的哈希值和相等性判断正确。上面的例子我们将字符串存入时,String类已经默认重写了这两个方法,所以可以正常工作。但是如果我们将自定义的对象存入HashSet中,会发生什么情况,如例:
例5-2 Demo8.java
import java.util.HashSet;
// 自定义Student类
class Student {
String id; // 学生ID
String name; // 学生姓名
// 默认构造函数
public Student() {
}
// 带参数的构造函数,用于初始化学生的ID和姓名
public Student(String id, String name) {
this.id = id;
this.name = name;
}
// 重写toString方法,返回学生的ID和姓名
public String toString() {
return id + ": " + name;
}
}
public class Demo8 {
public static void main(String[] args) {
// 创建一个HashSet集合,用于存储Student对象
HashSet<Student> set = new HashSet<>();
// 创建学生对象
Student stu1 = new Student("1", "Jack");
Student stu2 = new Student("2", "Rose");
Student stu3 = new Student("1", "Jack"); // 与stu1相同的ID和姓名
// 添加学生对象到集合中
set.add(stu1);
set.add(stu2);
set.add(stu3);
// 打印集合内容
System.out.println(set);
}
}
输出
[1:Jack, 2:Rose, 1:Jack]
例5-2中,我们定义了一个Student类,并重写了Object类的hashCode()方法和equals()方法,以保证对象的哈希值和相等性判断正确。然后创建了一个HashSet集合,并向其中添加了三个Student对象,其中两个对象有相同的ID和姓名。这是查看输出结果,发现出现了两个相同的学生信息"1:Jack",这样的信息应该被HashSet认定为重复信息,不允许同时出现。之所以没有去掉这样的重复元素,是因为在定义Student类的时候没有重写hashCode()和equals()方法,因此创建的两个学生对象stu1和stu3所引用的对象地址不同,所以HashSet认为它们是不同的对象,并存入集合中。
接下来进行对例5-2进行改写,重写hashCode()和equals()方法,以保证对象的哈希值和相等性判断正确。如例:
例5-3 Demo9.java
import java.util.HashSet;
// 自定义Student类
class Student {
String id; // 学生ID
String name; // 学生姓名
// 默认构造函数
public Student() {
}
// 带参数的构造函数,用于初始化学生的ID和姓名
public Student(String id, String name) {
this.id = id;
this.name = name;
}
// 重写toString方法,返回学生的ID和姓名
public String toString() {
return id + ": " + name;
}
// 重写hashCode方法,用于根据学生ID计算哈希值
public int hashCode() {
return id.hashCode();
}
// 重写equals方法,以便比较两个Student对象是否相等
public boolean equals(Object obj) {
// 判断是否为同一对象
if (this == obj) {
return true;
}
// 判断obj是否为Student实例
if (!(obj instanceof Student)) {
return false;
}
// 类型转换
Student stu = (Student) obj;
// 根据ID判断两个学生对象是否相等
return this.id.equals(stu.id);
}
}
public class Demo9 {
public static void main(String[] args) {
// 创建一个HashSet集合,用于存储Student对象
HashSet<Student> set = new HashSet<>();
// 创建学生对象
Student stu1 = new Student("1", "Jack");
Student stu2 = new Student("2", "Rose");
Student stu3 = new Student("1", "Jack"); // 与stu1相同的ID和姓名
// 添加学生对象到集合中
set.add(stu1);
set.add(stu2);
set.add(stu3); // 此处stu3与stu1相同,因此不会被添加到集合中
// 打印集合内容,学生stu3不会重复添加
System.out.println(set);
}
}
输出
[1:Jack, 2:Rose]
再修改后的例5-3中,我们定义了一个Student类,并重写了Object类的hashCode()方法和equals()方法。在hashCode()方法中返回了id属性的哈希值,在equals()方法中比较对象的id是否相等,并返回结果。当调用HashSet集合的add()方法添加stu3时,发现stu3于stu1的哈希值相同,并且stu1.equals(stu3)返回true,HashSet认为它们是相同的对象,因此不会被添加到集合中。
5.3 TreeSet 集合
TreeSet集合是Set接口的另一个实现类,内部采用平衡二叉树来存储元素,它可以保证集合中没有重复的元素,并对集合中的元素进行排序,默认情况下,TreeSet集合是按自然顺序排序的。TreeSet集合的排序方式是比较元素的大小,而不是比较元素的哈希值。
tip:平衡二叉树的原理不再赘述,有兴趣可自行了解。
针对TreeSet集合存储元素的特殊性,TreeSet在继承Set接口的基础上实现了一些特有的方法,如表:
表5-1 TreeSet特有方法
| 方法声明 | 功能描述 |
|---|---|
| Object first() | 返回第一个元素 |
| Object last() | 返回最后一个元素 |
| Object lower(Object e) | 返回小于e的最大元素,如果没有则返回null |
| Object floor(Object e) | 返回小于等于e的最大元素,如果没有则返回null |
| Object higher(Object e) | 返回大于e的最小元素,如果没有则返回null |
| Object ceiling(Object e) | 返回大于等于e的最小元素,如果没有则返回null |
| Object pollFirst() | 移除并返回第一个元素 |
| Object pollLast() | 移除并返回最后一个元素 |
接下来通过一个案例来学习TreeSet集合的使用,如例:
例5-4 Demo10.java
import java.util.TreeSet;
public class Demo10{
public static void main(String[] args){
//创建TreeSet集合
TreeSet set = new TreeSet();
//1. 向集合中添加元素
set.add(13);
set.add(8);
set.add(17);
set.add(17); //添加重复元素
set.add(1);
set.add(11);
set.add(15);
set.add(25);
System.out.println("创建的TreeSet集合的元素为:" + set);
//2. 获取首尾元素
Object o1 = set.first();
Object o2 = set.last();
System.out.println("首部元素为:"+o1+"\n尾部元素为:" + o2);
//3. 比较获取元素
System.out.println("集合中小于20的最大元素为:" + set.lower(20));
System.out.println("集合中小于等于15的最大元素为:" + set.floor(15));
System.out.println("集合中大于25的最大元素为:" + set.higher(25));
System.out.println("集合中大于等于25的最大元素为:" + set.ceiling(25));
//4. 删除元素
System.out.println("删除的第一个元素为:" + set.pollFirst());
System.out.println("删除第一个元素后的集合为:" + set);
System.out.println("删除的最后一个元素为:" + set.pollLast());
System.out.println("删除最后一个元素后的集合为:" + set);
}
}
输出
创建的TreeSet集合的元素为:[1, 8, 11, 13, 15, 17, 25]
首部元素为:1
尾部元素为:25
集合中小于20的最大元素为:17
集合中小于等于15的最大元素为:15
集合中大于25的最大元素为:null
集合中大于等于25的最大元素为:25
删除的第一个元素为:1
删除第一个元素后的集合为:[8, 11, 13, 15, 17, 25]
删除的最后一个元素为:25
删除最后一个元素后的集合为:[8, 11, 13, 15, 17]
由上面例5-4案例的输出结果可以看出,不论我们元素的添加顺序如何,输出集合的元素为升序排序,并且没有重复元素。这是因为每次存入时,都会将该元素与其他元素进行比较,最后再插入到有序的对象系列当中。通过first()和last()方法可以获取集合的首尾元素,通过lower()、floor()、higher()和ceiling()方法可以获取集合中小于、小于等于、大于、大于等于某元素的元素。通过pollFirst()和pollLast()方法可以删除集合中的首尾元素,并返回被删除的元素。
集合中的元素在进行比较时,都会调用compareTo()方法,该方法是Comparable接口定义的,所以要进行排序,必须实现Comparable接口。在实际开发中,我们还会存储一些自定义的数据类型,但是这些自定义的数据类型并没有实现Comparable接口,所以无法直接在TreeSet集合中进行排序。为了解决这个问题,Java提供了两种TreeSet的排序规则,分别是自然排序和定制排序。
5.3.1 自然排序
自然排序是指集合中的元素必须实现
Comparable接口,并提供compareTo()方法,TreeSet集合会根据compareTo()方法的返回值来默认进行升序排序。
接下来通过自定义的Teacher类为例子,演示自然排序的使用。如例:
例5-5 Demo11.java
import java.util.TreeSet;
// 定义Teacher类,实现Comparable接口以支持排序
class Teacher implements Comparable {
String name; // 教师姓名
int age; // 教师年龄
// 默认构造函数
public Teacher() {
}
// 带参数的构造函数,用于初始化教师的年龄和姓名
public Teacher(int age, String name) {
this.name = name;
this.age = age;
}
// 重写Comparable接口的compareTo()方法,用于比较两个Teacher对象
public int compareTo(Object obj) {
Teacher t = (Teacher) obj; // 强制类型转换为Teacher类
// 定义比较方式,先比较年龄,再比较姓名
if (this.age - t.age > 0) { // 如果当前对象的年龄大于被比较对象的年龄
return 1; // 返回1,表示当前对象在排序中较大
}
if (this.age - t.age == 0) { // 如果年龄相同
return this.name.compareTo(t.name); // 进行姓名字典序比较
}
return -1; // 否则,返回-1,表示当前对象在排序中较小
}
// 重写toString()方法,返回年龄和姓名,便于打印观察
public String toString() {
return age + ": " + name;
}
}
public class Demo11 {
public static void main(String[] args) {
// 创建一个TreeSet集合,用于存储可排序的Teacher对象
TreeSet<Teacher> t = new TreeSet<>();
// 添加不同的教师对象到集合中
t.add(new Teacher(19, "Jack")); // 添加年龄为19,姓名为Jack的教师
t.add(new Teacher(20, "Rose")); // 添加年龄为20,姓名为Rose的教师
t.add(new Teacher(19, "Tom")); // 添加年龄为19,姓名为Tom的教师
// 打印集合内容,显示按年龄和姓名排序后的结果
System.out.println(t);
}
}
输出
[19:Jack, 19:Tom, 20:Rose]
5.3.2 定制排序
有时候我们自定义的数据类型所在的类没有实现
Comparable接口或者对于实现了接口的类不想按照定义的compareTo()方法进行排序。比如:我们希望存储的元素不按照英文字母排序,而是按照长度排序,这时就可以在创建TreeSet集合时就自定义一个比较器来对元素进行定制排序功能。
通过自定义一个比较器,我们可以比较两个元素的长度,并返回比较结果,从而实现定制排序功能。如例:
例5-6 Demo12.java
import java.util.TreeSet;
import java.util.Comparator;
// 定义比较器类,实现Comparator接口
class MyComparator implements Comparator {
// 定制排序方式
public int compare(Object obj1, Object obj2) {
// 强制类型转换为String
String s1 = (String) obj1;
String s2 = (String) obj2;
// 比较字符串长度,返回长度差
return s1.length() - s2.length();
}
}
public class Demo12 {
public static void main(String[] args) {
// 1. 创建集合时,传入Comparator接口实现定制排序
TreeSet<String> ts1 = new TreeSet<>(new MyComparator()); // 使用自定义比较器
ts1.add("Jack"); // 添加字符串
ts1.add("Alibaba"); // 添加字符串
ts1.add("Tom"); // 添加字符串
System.out.println(ts1); // 打印按照字符串长度排序的结果
// 2. 创建集合时,使用Lambda表达式定制排序规则
TreeSet<String> ts2 = new TreeSet<>((obj1, obj2) -> {
// 强制类型转换为String
String s1 = (String) obj1;
String s2 = (String) obj2;
// 比较字符串长度,返回长度差
return s1.length() - s2.length();
});
ts2.add("Jack"); // 添加字符串
ts2.add("Alibaba"); // 添加字符串
ts2.add("Tom"); // 添加字符串
System.out.println(ts2); // 打印按照字符串长度排序的结果
}
}
输出
[Tom, Jack, Alibaba]
[Tom, Jack, Alibaba]
tip:在使用TreeSet集合存储数据时,TreeSet集合会对存入元素进行比较排序,所以为了保证程序正常运行,一定要保证存入集合的元素是同一数据类型。
6. Map 接口
6.1 Map 接口简介
Map接口是一种双列集合,它的每个元素都包含一个键对象Key和值对象Value,键值之间存在一种对应关系,称为映射。Map中的映射关系是一对一的,即每个键只能对应唯一的值。其中键对象Key和值对象Value可以是任意数据类型,并且键对象Key不允许重复。
为了方便Map接口的学习,我们先来看看Map接口的常用方法,如表所示:
表6-1 Map接口常用方法
| 方法声明 | 功能描述 |
|---|---|
| void put(Object key, Object value) | 向Map集合中添加指定键值映射的元素 |
| int size() | 返回Map集合中键值对的个数 |
| Object get(Object key) | 返回指定键的映射值 |
| boolean containsKey(Object key) | 判断Map集合中是否包含指定键对象key |
| boolean containsValue(Object value) | 判断Map集合中是否包含指定值对象value |
| Object remove(Object key) | 删除并返回Map集合中指定键对象Key的简直映射元素 |
| void clear() | 清空Map集合中的键值映射元素 |
| Set keySet() | 将Map集合中的所有键对象返回为一个Set集合 |
| Collection values() | 将Map集合中的所有值对象返回为一个Collection集合 |
| Set<Map,Entry<Key,Value>> entrySet() | 将Map集合转换为存储元素类型为Map的Set集合 |
| Object getOrDefault(Object key, Object defaultValue) | 返回指定键的映射值,如果不存在则默认返回defaultValue |
| void forEach(BiConsumer action) | 通过传入一个函数式接口对Map集合进行遍历 |
| Object putIfAbsent(Object key, Object value) | 向Map集合中添加指定键值映射的元素,如果该键不存在则添加,否则返回已存在的值对象Value |
| Object replace(Object key, Object value) | 将Map集合中指定键对象Key所映射值修改为value,并返回原值old value |
| boolean remove(Object key, Object value) | 删除Map集合中简直映射同时匹配的元素 |
6.2 HashMap 集合
HashMap集合是Map接口的主要实现类,该集合的键和值允许为空,但是键不能重复,且元素无序。HashMap集合的底层实现是哈希表,其实就是通过数组和链表来实现,数组是HashMap的主体结构,而链表则主要是为了解决哈希值冲突而存在的分支结构。正是因为这种特殊结构,所以对元素的增删改查效率都比较高。
图 6-2 HashMap集合内部结构及存储原理图
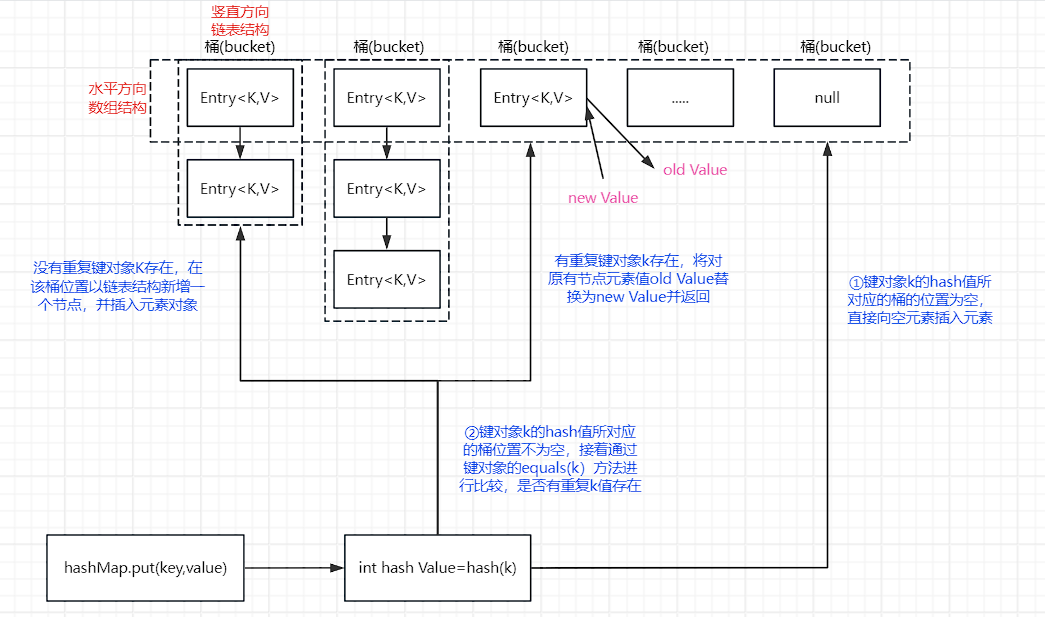
如图所示,水平方向以数组结构为主体,竖直方向以链表结构进行结合后就是HashMap中的哈希表结构.水平方向数组的长度称为HashMap集合的容量,竖直方向每个元素位置对应的链表结构成为一个桶(bucket),每个桶的位置在集合中都有对应的桶值,用于快速定位集合元素添加,查找时的位置。
每当向HashMap集合中添加元素时,首先会调用键对象k的hash(k)方法,得到k的哈希值,然后通过k的哈希值计算出在数组中的索引位置(桶的位置),如果该位置上没有元素,则直接将元素添加到该位置上;如果该位置上已经有元素,则会调用键对象k的equals(k)方法来判断该元素是否和k相等,如果相等,则直接替换该元素的值;如果不相等,则会在该位置上创建一个新的链表节点,将该元素添加到链表中。
接下来通过一个案例来学习HashMap集合的使用,如例:
例6-1 Demo13.java
import java.util.HashMap;
import java.util.Map;
public class Demo13 {
public static void main(String[] args){
//创建HashMap对象
Map map = new HashMap();
//1. 向map存储键值对元素
map.put("Jack",18);
map.put("Tom",19);
map.put("Rose",19); // 添加重复值,但键不一样
map.put("Milk",20);
map.put("Rose",21); //添加重复键 但是值不一样
map.put("Rose",25); //添加重复键 但是值不一样
System.out.println(map);
//2. 查看键对象是否存在
boolean flag = map.containsKey("Rose");
boolean flag1 = map.containsKey("Ming");
System.out.println("键Rose存在吗:"+flag+"\n键Ming存在吗:" + flag1);
//3. 获取指定键对象映射的值
Object obj = map.get("Rose");
System.out.println("键Rose的值为:"+obj);
//4. 获取集合中的键对象和值对象集合
System.out.println("键对象的集合为:" + map.keySet());
System.out.println("值对象的集合为:" + map.values());
System.out.println("键值对象的集合为:" + map.entrySet());
//5. 替换指定键对象映射的值
Object obj2 = map.replace("Rose",22);
System.out.println("替换指定键对象映射的值为:" + obj2);
System.out.println("当前集合为:" + map);
//6. 删除指定键对象映射的键值对元素
boolean flag4 = map.remove("Rose",22);
System.out.println("删除指定键对象映射的键值对元素为:" + flag4);
System.out.println("当前集合为:" + map);
}
}
输出
{Tom=19, Rose=25, Jack=18, Milk=20}
键Rose存在吗:true
键Ming存在吗:false
键Rose的值为:25
键对象的集合为:[Tom, Rose, Jack, Milk]
值对象的集合为:[19, 25, 18, 20]
键值对象的集合为:[Tom=19, Rose=25, Jack=18, Milk=20]
替换指定键对象映射的值为:25
当前集合为:{Tom=19, Rose=22, Jack=18, Milk=20}
删除指定键对象映射的键值对元素为:true
当前集合为:{Tom=19, Jack=18, Milk=20}
例子中,我们创建了一个HashMap集合,并向其中添加了一些键值对元素,然后通过containsKey()方法判断键对象是否存在,通过get()方法获取指定键对象映射的值,通过keySet()方法获取集合中的键对象集合,通过values()方法获取集合中的值对象集合,通过entrySet()方法获取集合中的键值对对象集合,通过replace()方法替换指定键对象映射的值,通过remove()方法删除指定键对象映射的键值对元素。从输出结构可以看出,Map集合中的键具有唯一性,当我们向集合中添加已存在的键时,会覆盖之前已存在的键值元素。
6.3 Map集合遍历
Map集合的遍历同List类似,有两种方法,一是通过Iterator迭代器迭代遍历,二是通过Lambda表达式特性的forEach()方法传入函数式接口遍历。
6.3.1 通过Iterator迭代器遍历
使用
Iterator迭代器遍历Map集合,需要先将Map集合转换为Iterator对象,然后进行遍历。将Map集合转换为Iterator对象的方法有两种,一种是调用entrySet()方法,将Map集合转换为Set集合,再调用iterator()方法,将Set集合转换为Iterator对象;另一种是调用keySet()方法,将Map集合转换为Set集合,再调用iterator()方法,将Set集合转换为Iterator对象。
如例:
例6-2 Demo14.java
import java.util.HashMap; // 导入HashMap类
import java.util.Iterator; // 导入Iterator接口
import java.util.Set; // 导入Set接口
import java.util.Map; // 导入Map接口
public class Demo14 {
public static void main(String[] args) {
// 创建HashMap对象
Map map = new HashMap();
// 向集合中添加元素(键值对)
map.put("Jack", 20); // 添加键 "Jack" 对应值 20
map.put("Rose", 21); // 添加键 "Rose" 对应值 21
map.put("Mike", 22); // 添加键 "Mike" 对应值 22
// 打印集合内容
System.out.println(map);
// 第一种方法:先将Map集合中的所有键转换为Set集合,再获取Iterator对象
System.out.println("第一种方法 先将Map集合中的所有键转换为Set集合,在获取Iterator对象:");
Set set = map.keySet(); // 获取所有键的Set集合
// 获取Iterator对象
Iterator iterator = set.iterator(); // 创建迭代器
while (iterator.hasNext()) { // 循环遍历
// 获取键对象key
Object key = iterator.next(); // 获取下一个键
// 通过key获取值
System.out.println(key + ":" + map.get(key)); // 打印键和值
}
// 第二种方法:先将Map集合的所有键值对转换为Set集合,再获取Iterator对象
System.out.println("第二种方法 先将Map集合的所有键值对转换为Set集合,在获取Iterator对象:");
Set entrySet = map.entrySet(); // 获取所有键值对的Set集合
// 获取Iterator对象
Iterator iterator1 = entrySet.iterator(); // 创建迭代器
while (iterator1.hasNext()) { // 循环遍历
// 获取键值对
Map.Entry entry = (Map.Entry)iterator1.next(); // 获取下一个键值对
// 通过Map.Entry获取键和值
System.out.println(entry.getKey() + ":" + entry.getValue()); // 打印键和值
}
}
}
输出
{Mike=22, Rose=21, Jack=20}
第一种方法 先将Map集合中的所有键转换为Set集合,在获取Iterator对象:
Mike:22
Rose:21
Jack:20
第二种方法 先将Map集合的所有键值对转换为Set集合,在获取Iterator对象:
Mike:22
Rose:21
Jack:20
第一种遍历方法:使用 keySet() 方法获取 map 中所有键的 Set 集合。
通过 Iterator 遍历这些键,使用 map.get(key) 方法获取对应的值,并打印出每一个键值对。
第二种遍历方法:使用 entrySet() 方法获取 map 中所有键值对的 Set 集合。
同样通过 Iterator 遍历这些键值对,使用 Map.Entry 获取每个键值对中的键和值,并打印出结果。这种方法遍历的效率更高,因为可以直接访问键和值。
tip:Entry是Map接口内部类,每个Map.Entry对象代表Map中的一个键值对,然后迭代Set集合,获得每一个映射对象,并分别调用映射对象的getKey()和getValue()方法,就可以获得键和值。
6.3.2 通过forEach()方法遍历
通过一个案例来学习如何使用forEach()方法遍历Map集合,如例:
例6-3 Demo15.java
import java.util.HashMap;
import java.util.Map;
public class Demo15{
public static void main(String[] args){
// 创建HashMap对象
Map map = new HashMap();
// 向集合中添加元素(键值对)
map.put("Jack", 20); // 添加键 "Jack" 对应值 20
map.put("Rose", 21); // 添加键 "Rose" 对应值 21
map.put("Mike", 22); // 添加键 "Mike" 对应值 22
// 打印集合内容
System.out.println(map);
//使用forEach循环遍历
map.forEach((key,value) -> System.out.println(key + ":" + value));
}
}
输出
{Mike=22, Rose=21, Jack=20}
Mike:22
Rose:21
Jack:20
例子6-3中,我们创建了一个HashMap集合,并向其中添加了一些键值对元素,然后通过forEach(BiConsumer action)方法传入一个函数式接口BiConsumer。forEach()方法在执行时,会自动遍历集合元素的键和值并将结果逐个传递Lambda表达式的形参。
6.3.3 LinkedHashMap 集合
LinkedHashMap集合是HashMap集合的子类,它继承了HashMap集合中的所有方法,LinkedHashMap集合的内部实现与HashMap集合类似,也是通过数组和链表来实现的。但是LinkedHashMap集合在实现上添加了对元素的顺序的维护。LinkedHashMap集合中的元素是有序的,按照添加的顺序来存储。即LinkedhashMap集合的添加顺序与迭代的顺序是一致的。
通过案例来学习LinkedHashMap集合的使用,如例:
例6-4 Demo16.java
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
public class Demo16{
public static void main(String[] args){
// 创建HashMap对象
Map map = new HashMap();
// 创建LinkedHashMap对象
Map map1 = new LinkedHashMap();
// 向HashMap集合中添加元素(键值对)
map.put("Jack", 20); // 添加键 "Jack" 对应值 20
map.put("Rose", 21); // 添加键 "Rose" 对应值 21
map.put("Mike", 22); // 添加键 "Mike" 对应值 22
// 向LinkedHashMap集合中添加元素(键值对)
map1.put("Jack", 23); // 添加键 "Jack" 对应值 20
map1.put("Rose", 21); // 添加键 "Rose" 对应值 21
map1.put("Mike", 22); // 添加键 "Mike" 对应值 22
// 打印集合内容
System.out.println(map);
System.out.println("分隔符================");
System.out.println(map1);
//使用forEach循环遍历
map.forEach((key,value) -> System.out.println(key + ":" + value));
System.out.println("分隔符================");
map1.forEach((key,value) -> System.out.println(key + ":" + value));
}
}
输出
{Mike=22, Rose=21, Jack=20}
分隔符================
{Jack=23, Rose=21, Mike=22}
Mike:22
Rose:21
Jack:20
分隔符================
Jack:23
Rose:21
Mike:22
tip:一般情况下,使用最多的还是HashMap,但如果要求输入与输出的顺序相同,那么用LinkedHashMap集合就比较合适。
6.4 TreeMap 集合
TreeMap集合是Map接口的主要实现类,该集合的键和值允许为空,且元素有序。TreeMap集合的底层实现是红黑树,它是一种平衡二叉树,具有快速查找、插入和删除操作的特点。TreeMap集合中的元素是有序的,按照添加的顺序来存储。类似于TreeSet集合,TreeMap集合中的元素也是按照Comparable接口的compareTo()方法的返回值来排序的。
通过案例来学习TreeMap集合的使用,如例:
例6-5 Demo17.java
import java.util.Map;
import java.util.TreeMap;
public class Demo17{
public static void main(String [] args){
//创建集合对象
Map map = new TreeMap();
map.put(19,"Tom");
map.put(21,"Mike");
map.put(20,"Jack");
System.out.println(map);
}
}
输出
{19=Tom, 20=Jack, 21=Mike}
例6-5中,我们创建了一个TreeMap集合,并向其中添加了一些元素,然后打印出集合内容。从结果可以看出,TreeMap集合中的元素是按照自然顺序进行了排序。这是因为添加的元素中键对象的String类实现了Comparable接口。
同TreeSet集合一样,在使用TreeMap集合时,也可以通过自定义规则器对所有的键进行定制排序。
接下来通过一个案例来演示如何自定义排序规则:
例6-6 Demo18.java
import java.util.Map;
import java.util.TreeMap;
import java.util.Comparator;
class MyComparator implements Comparator{
public int compare(Object obj1,Object obj2){
//int类型的键 从大到小排序*/
int key1 = (int)obj1;
int key2 = (int)obj2;
return key2 - key1;
/*
//String 类型 从大到小排序
String key1 = (String)obj1;
String key2 = (String)obj2;
return key2.compareTo(key1);
*/
}
}
public class Demo18{
public static void main(String [] args){
//创建集合对象
Map map = new TreeMap(new MyComparator());
// int类型的键
map.put(19,"Tom");
map.put(21,"Mike");
map.put(20,"Jack");
/*
//String类型的键
map.put("19","Tom");
map.put("21","Mike");
map.put("20","Jack");
*/
System.out.println(map);
}
}
输出
{21=Mike, 20=Jack, 19=Tom}
例6-6中,我们创建了一个TreeMap集合,并向其中添加了一些元素,然后打印出集合内容。从结果可以看出,TreeMap集合中的元素按照自定义的排序规则进行了排序。
tip:TreeMap集合的排序规则是通过compareTo()方法来实现的,如果自定义的键对象没有实现Comparable接口,那么就需要自定义排序规则。
6.5 Properties 集合
Map还有个实现类Hashtable,它和HashMap集合类似,也是通过数组和链表来实现的。但是Hashtable集合是线程安全的,而HashMap集合不是线程安全的。另外在使用方面,Hashtable的效率也不及HashMap,所以基本上使用的都是HashMap集合。但是Hashtable类有一个子类Properties在实际应用中非常重要。Properties主要用来存储字符串类型的键和值,实际开发中,经常使用Proerties集合类来存取配置文件。
假设有一个文本编辑工具,要求默认背景颜色为红色,字体大小14px,语言为中文,这些要求就可以使用Properties集合类对应的properties文件进行配置,如例:
例6-7 test.properties
background=red
font-size=14px
language=chinese
接下来,通过一个案例来学习Properties集合类如何对properties配置文件进行读取和写入操作(假设test.properties文件在运行目录),如例:
例6-8 Demo19.java
import java.util.Properties;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class Demo19{
public static void main(String[] args) throws Exception{
//1. 通过Properties进行属性文件读取操作
Properties pps = new Properties();
//加载要读取的文件test.properties
pps.load(new FileInputStream("test.properties"));
//遍历test.properties
pps.forEach((key,value) -> System.out.println(key + "=" + value));
//2. 通过Properties属性进行写入操作
//指定要写入操作的文件名称和位置
FileOutputStream out = new FileOutputStream("test.properties");
//向Properties类文件进行写入键值对信息
pps.setProperty("Charset","UTF-8");
//将此Properties集合中新增键值对信息写入配置文件
pps.store(out,"新增charset编码");
}
}
输出
background=red
font-size=14px
language=chinese
Charset=UTF-8
例6-8中,首先创建了Properties集合对象,然后通过I/O流的形式读取了配置文件的内容并进行遍历。完成了Properties集合的读取操作。接着同样通过I/O流的形式指定了要进行写入操作的文件地址和名称,使用setProperty()方法向Properties集合中添加了新的键值对信息,并使用store()方法将新增的键值对信息写入配置文件。
tip:Properties集合类可以用来读取配置文件,也可以用来写入配置文件。
7. 泛型
通过前面的学习,了解到集合可以存储任意类型的对象,但是当把一个对象存入集合后,集合就会“忘记”这个对象的类型,将该对象从集合中取出以后,这个对象的编译类型就变成了
Object类型。这就造成了一些问题,比如:当我们从集合中取出一个对象时,我们无法确定它的类型,如果进行强制类型转换的时候,就很容易出错。
接下来通过一个案例来演示这种情况,如例:
例7-1 Demo20.java
import java.util.ArrayList;
public class Demo20{
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add("String对象"); //添加字符串对象
list.add(20); //添加Integer对象
list.forEach(o-> {
//将Object类型强制转换为String
String str = (String)o;
System.out.println(str);
});
}
}
输出
String对象
Exception in thread "main" java.lang.ClassCastException: class java.lang.Integer cannot be cast to class java.lang.String (java.lang.Integer and java.lang.String are in module java.base of loader 'bootstrap')
at Demo20.lambda$main$0(Demo20.java:11)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
at Demo20.main(Demo20.java:10)
上面案例中,我们创建了一个ArrayList集合,并向其中添加了字符串对象和整数对象。然后通过forEach()方法遍历集合,并将集合中的对象强制转换为字符串类型。但是由于整数对象不能转换为字符串类型,所以会抛出ClassCastException异常。
为了解决这个问题,Java引入了"参数化类型(parameterized type)"这个概念,也就是泛型。泛型可以限定操作的数据类型,在定义集合时,可以使用<参数化类型>的方式指定该集合中存储的数据类型,具体格式如下:
ArrayList<参数化类型> list = new ArrayList<参数化类型>();
接下来对上面的例子进行修改,使用泛型来限定ArrayList集合中只能存储String类型的数据,如下:
ArrayList<String> list = new ArrayList<String>();
修改之后在运行,发现编译就出现了错误,如下:
Demo20.java:10: 错误: 不兼容的类型: int无法转换为String
list.add(20);
编译报错的原因是因为修改后的代码限定了集合元素的数据类型,ArrayList<String>这样的集合只能存放String类型的数据。程序在编译时,编译器检查出Integer类型的数据元素与List集合规定的元素不匹配,编译不通过。这样就可以在编译时期解决问题,避免程序运行时报错。
接下来使用泛型再次对案例进行改写,如下所示:
例7-2 Demo21.java
import java.util.ArrayList;
public class Demo21{
public static void main(String[] args){
// ArrayList list = new ArrayList();
// 修改为泛型,限定String类型
ArrayList<String> list = new ArrayList<String>();
list.add("String对象"); //添加字符串对象
list.add("20");
//因为使用了泛型限定,所以编译器自动识别元素为String类型,不需要强制类型转换
list.forEach(str-> {
System.out.println(str);
});
}
}
输出
String对象
20
tip:ArrayList<String> list = new ArrayList<String>();中,后面的参数化类型可以省略,例如:ArrayList<String> list = new ArrayList<>();
8. 常用工具类
8.1 Collections 工具类
Java中,针对集合的操作非常频繁,例如元素排序,查找元素等。针对这些常见操作,Java提供了一个工具类专门用来操作集合,这个工具类就是
Collections。它位于java.util包中,提供了一系列静态方法,用于对集合进行操作。
8.1.1 添加、排序操作
Collections工具类提供了一系列方法用于对集合进行添加,排序等操作,如表8-1-1所示:
表8-1-1 Collections工具类常用 添加 和 排序 方法
| 方法声明 | 功能描述 |
|---|---|
| static | 将所有指定元素添加到指定集合c中 |
| static void reverse(List<?> list) | 反转指定列表list中的元素顺序 |
| static void shuffle(List<?> list) | 随机排序指定列表list中的元素 |
| static void sort(List<?> list) | 对指定列表list中的元素进行自然排序 |
| static void swap(List<?> list, int i, int j) | 将指定列表list中下标i和下标j处元素进行交换 |
接下来通过案例来演示表中的方法,如下:
例8-1 Demo22.java
import java.util.Collections;
import java.util.ArrayList;
public class Demo22{
public static void main(String[] args){
ArrayList<Integer> list = new ArrayList<>();
list.add(13);
list.add(20);
list.add(3);
list.add(56);
list.add(44);
//输出集合中的元素
System.out.println(list);
// 1. 将所有指定元素添加到集合中
Collections.addAll(list,88,77,34);
System.out.println("添加后的集合为:" + list);
// 2. 反转集合中元素的顺序
Collections.reverse(list);
System.out.println("反转后的集合为:" + list);
// 3. 随机排序集合中元素的顺序
Collections.shuffle(list);
System.out.println("随机排序后的集合为:" + list);
// 4. 自然排序集合中元素的顺序
Collections.sort(list);
System.out.println("自然排序后的集合为:" + list);
// 5. 指定集合中元素下标 1 和 4 的元素进行交换
Collections.swap(list,1,4);
System.out.println("交换后的集合为:" + list);
}
}
输出
[13, 20, 3, 56, 44]
添加后的集合为:[13, 20, 3, 56, 44, 88, 77, 34]
反转后的集合为:[34, 77, 88, 44, 56, 3, 20, 13]
随机排序后的集合为:[44, 13, 56, 77, 88, 3, 34, 20]
自然排序后的集合为:[3, 13, 20, 34, 44, 56, 77, 88]
交换后的集合为:[3, 44, 20, 34, 13, 56, 77, 88]
8.1.2 查找、替换操作
Collections工具类还提供了一系列方法用于查找和替换集合中的元素,如表8-1-2所示:
表8-1-2 Collections工具类常用 查找 和 替换 方法
| 方法声明 | 功能描述 |
|---|---|
| static void binarySearch(List<?> list, Object key) | 使用二分法搜索指定对象在集合中的索引、查找的List集合必须是有序的 |
| static Object max(Collection col) | 根据元素的自然顺序,返回集合中最大的元素 |
| static Object min(Collection col) | 根据元素的自然顺序,返回集合中最小的元素 |
| static boolean replaceAll(List list, Object oldVal, Object newVal) | 替换列表list中所有等于oldVal的元素为newVal |
接下来通过案例来演示表中的方法,如下:
例8-2 Demo23.java
import java.util.Collections;
import java.util.ArrayList;
public class Demo23{
public static void main(String[] args){
ArrayList<Integer> list = new ArrayList<>();
// 1. 将所有指定元素添加到集合中
Collections.addAll(list,48,27,14,-3,3);
System.out.println("添加后的集合为:" + list);
System.out.println("集合中最大的元素为:" + Collections.max(list));
System.out.println("集合中最小的元素为:" + Collections.min(list));
// 2. 将集合中的3用5替换掉
Collections.replaceAll(list,3,5);
System.out.println("替换后的集合为:" + list);
// 3. 使用二分法查找元素,使用前必须保证元素有序
Collections.sort(list); //排序,确保元素有序
System.out.println("排序后的集合为:" + list);
System.out.println("查找元素14的下标为:" + Collections.binarySearch(list,14));
}
}
输出
添加后的集合为:[48, 27, 14, -3, 3]
集合中最大的元素为:48
集合中最小的元素为:-3
替换后的集合为:[48, 27, 14, -3, 5]
排序后的集合为:[-3, 5, 14, 27, 48]
查找元素14的下标为:2
tip:Collections工具类还提供了很多常用方法,想要了解更多可以参考API文档。
8.2 Arrays 工具类
在
java.util包中,除了针对集合提供了Collections工具类,还提供了针对数组的工具类Arrays。Arrays工具类提供了一系列方法用于操作数组。如表8-2-1所示:
表8-2-1 Arrays工具类常用 方法
| 方法声明 | 功能描述 |
|---|---|
| static void sort(Object[] arr) | 对指定数组arr进行排序 |
| static int binarySearch(Object[] arr, Object key) | 使用二分法搜索指定对象在数组中的索引,同样要求,数组必须有序 |
| static int[] copyOfRange(int[] original,int from,int to) | 将指定数组的指定范围复制到一个新数组中,包含from,不包含to |
| static void fill(Object[] a,Object val) | 将指定数组a中的元素全部赋值为指定值val |
接下来通过案例来学习这些方法,如下:
例8-3 Demo24.java
import java.util.Arrays;
public class Demo24{
public static void main(String[] args){
// 创建int类型数组
int[] arr = {19,20,3,15,44};
System.out.print("排序前数组:");
printArray(arr);
// 1. 使用sort对数组进行排序
Arrays.sort(arr);
System.out.print("\n排序后数组:");
printArray(arr);
// 2. 使用binarySearch查找元素 同样要求,数组必须有序
System.out.print("数组中 15 的下标为:" + Arrays.binarySearch(arr,15));
// 3. 使用copyOfRange 方法拷贝 下标1到3 元素 ,包含1 而不包含3
int [] arr1 = Arrays.copyOfRange(arr,1,3);
System.out.print("\n拷贝后的新数组为:");
printArray(arr1);
// 4. 使用fill 方法替换所有元素
Arrays.fill(arr,100);
System.out.print("\n替换所有元素后的数组为:");
printArray(arr);
}
//定义打印数组方法,便于打印输出
static void printArray(int [] arr){
System.out.print("[");
for(int i =0; i<arr.length;i++){
if(i != arr.length -1){
System.out.print(arr[i] + ",");
}else{
System.out.print(arr[i] + "]");
}
}
}
}
输出
排序前数组:[19,20,3,15,44]
排序后数组:[3,15,19,20,44]数组中 15 的下标为:1
拷贝后的新数组为:[15,19]
替换所有元素后的数组为:[100,100,100,100,100]
9. 聚合操作
9.1 聚合操作概述
在开发中,多数情况会涉及对集合、数组中元素的操作,在JDK8之前都是通过普通的循环遍历每一个元素,还会穿插一些if条件选择性的对元素进行查找、过滤、修改等操作,这种方式非常繁琐,并且代码可读性差。为此,JDK8中增加了一个
Stream接口,该接口可以将集合、数组中的元素转换为Stream流的形式,并结合Lambda表达式的优势进一步简化集合、数组中元素的查找、过滤、转换等操作,这一新功能被称为聚合操作。
在程序中,使用聚合操作并没有绝对的语法规范,根据实际流程,主要分为以下三个步骤:
- 将
原始集合或数组对象转换为Stream流对象。 - 对
Stream流对象中的元素进行一系列的过滤、查找等中间操作,然后仍然返回一个Stream流对象。 - 对
Stream流进行遍历,统计,收集等终结操作,获取想要的结果。
接下来,根据上面聚合操作的三个步骤,通过案例来演示聚合操作的基本用法,如下:
例9-1 Demo25.java
import java.util.ArrayList;
import java.util.stream.Stream;
import java.util.Collections;
public class Demo25{
public static void main(String[] args){
ArrayList<String> list = new ArrayList<>();
// 集合中添加元素
Collections.addAll(list,"张三","李四","王五","张明","张全蛋");
// 1. 将集合转换为Stream流对象
Stream<String> stream1 = list.stream();
// 对Stream流中的元素进行过滤 过滤出姓张的人
Stream<String> stream2 = stream1.filter(str -> str.startsWith("张"));
// 进行截取操作 ,只保留前两个
Stream<String> stream3 = stream2.limit(2);
//进行终结操作,对Stream流进行遍历
stream3.forEach(str -> System.out.println(str));
System.out.println("分割线===============");
// 2. 使用链式表达式完成操作
list.stream().filter(str -> str.startsWith("张"))
.limit(2)
.forEach(str -> System.out.println(str));
}
}
输出
张三
张明
分割线===============
张三
张明
例9-1中,首先创建了ArrayList集合,然后使用Collections工具类向集合中添加了元素。接着根据聚合操作的三个步骤实现了对集合对象的聚合操作,对集合中的元素使用Stream流的形式进行了了filter() 过滤、limit() 截取、forEach() 遍历等操作。最后,使用了链式表达式(也称为操作管道流)对操作进行了简化。
tip:JDK8中使用聚合操作时,出现了两个新名词中间操作和终结操作。中间操作指的是对Stream流对象进行的一系列操作,如filter() 过滤、limit() 截取等,这些操作不会立即执行,而是返回一个新的Stream流对象,可以继续进行后续的操作。终结操作指的是对Stream流对象进行的最后操作,如forEach() 遍历、count() 统计、collect() 收集等,这些操作会立即执行,并返回结果。
9.2 创建Stream流对象
9.1介绍了聚合操作的主要使用步骤,其中首要问题就是如何创建Stream流对象。聚合操作针对的就是可迭代数据进行的操作,如集合、数组等,所以创建Stream流对象起始就是将集合、数组等通过一些方法转换为Stream流对象。
Java提供了多种创建Stream流对象的方法,分别如下:
- 所有的
Collections集合都可以使用stream()静态方法方法创建Stream流对象。 Stream类中的静态方法of()可以将引用类型数组、基本类型包装类数组和单个元素转换为Stream流对象。Arrays类中的静态方法stream()可以数组转换为Stream流对象。
接下来,通过案例来学习这些方法,如下:
例9-2 Demo26.java
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
import java.util.Arrays;
public class Demo26{
public static void main(String[] args){
//创建数组
Integer[] arr = {10,20,3,45,6};
// 将数组转换为List集合
List<Integer> list = Arrays.asList(arr);
// 1. 使用stream()静态方法创建Stream对象
Stream<Integer> stream = list.stream();
stream.forEach(System.out::println);
System.out.println("==================");
// 2. 使用静态方法of()创建Stream对象
Stream<Integer> stream1 = Stream.of(arr);
stream1.forEach(System.out::println);
System.out.println("==================");
// 3. 使用Arrays工具类中的stream()方法创建Stream流对象
Stream<Integer> stream2 = Arrays.stream(arr);
stream2.forEach(System.out::println);
}
}
输出
10
20
3
45
6
==================
10
20
3
45
6
==================
10
20
3
45
6
例9-2中,首先创建了Integer类型的数组arr,然后使用Arrays工具类中的asList()方法将数组转换为List集合。接着,使用了stream()方法、of()方法和Arrays工具类中的stream()方法创建了Stream流对象。最后,使用forEach()方法对Stream流对象中的元素进行了遍历。
tip:注意Stream流对象中针对的是基本类型包装类,所以创建int数组时要使用包装类Integer。并且,只针对Collections接口对象提供了stream()静态方法获取流对象,并未对Map集合提供相关方法,Map集合想要创建Stream流对象则必须通过Map集合的keySet()、values()、entrySet()等方法将Map集合转换为Set单列集合,然后再使用Set集合中的stream()方法获取对应键、值集合的Stream流对象。
9.3 Stream流的常用方法
JDK 8 为聚合操作中的
Stream流对象提供了非常丰富的方法,这些方法被划分为中间操作和终结操作两种类型。两种类型操作方法的本质区别就是方法的返回值,只要返回值不是Stream类型的就是终结操作,将会终结当前流模型,其他操作都属于中间操作。如表9-1-1所示:
表9-1-1 Stream流常用方法
| 方法声明 | 功能描述 |
|---|---|
| Stream | 将指定流对象中的元素进行过滤,并返回过滤的元素 |
| Stream | 将流中的元素按规则映射到另一个流中 |
| Stream | 删除掉流中重复的元素 |
| Stream | 对流中的元素进行自然排序 |
| Stream | 截取流中的元素,只保留指定数量的元素 |
| Stream | 跳过流中的前n个元素,返回剩余元素 |
| long count() | 统计流中元素的数量 |
| static | 将两个流对象合并为一个流对象 |
| R collect(Collector<? super T,A,R> collector) | 将流中的元素收集到一个结果容器中(如集合) |
| Object[] toArray | 将流中的元素转换为数组 |
| void forEach(Consumer<? super T> action) | 对流中的元素进行遍历 |
表中只是列出了Stream流对象的常用方法,其中一些方法还有多个重载方法,具体的用法可以参考API文档。接下来,通过案例来学习这些常用方法,如下:
例9-3 Demo27.java
import java.util.stream.Stream;
import java.util.stream.Collectors;
import java.util.List;
public class Demo27 {
public static void main(String[] args) {
// 1. 遍历
// 通过字符串创建流对象
Stream<String> stream = Stream.of("张三", "张全蛋", "王五");
// 遍历流并输出每个元素
stream.forEach(System.out::println);
System.out.println("============================");
// 2. 过滤
Stream<String> stream1 = Stream.of("张三", "张全蛋", "王五");
// 使用filter方法过滤出姓张且长度大于2的元素
stream1.filter(str -> str.startsWith("张") && str.length() > 2)
.forEach(System.out::println);
System.out.println("============================");
// 3. 排序和删除重复元素
Stream<Integer> stream2 = Stream.of(10, 51, 3, 66, 41, 18, 3);
// 对流进行排序,删除重复元素,并遍历输出
stream2.sorted()
.distinct()
.forEach(System.out::println);
System.out.println("============================");
// 4. 映射
Stream<String> stream3 = Stream.of("a1", "c1", "c3", "c2");
// 过滤出以c开头的元素,转换为大写并排序
stream3.filter(str -> str.startsWith("c")) // 过滤出c开头的元素
.map(str -> str.toUpperCase()) // 对流元素进行映射,字符转换为大写
.sorted() // 排序
.forEach(System.out::println); // 遍历输出
System.out.println("============================");
// 5. 截取
Stream<String> stream4 = Stream.of("张三", "张全蛋", "王五", "李四");
// 跳过第一个元素,保留接下来两个元素并输出
stream4.skip(1) // 跳过第一个元素
.limit(2) // 保留前两个元素
.forEach(System.out::println); // 遍历输出
System.out.println("============================");
// 6. 收集
Stream<String> stream5 = Stream.of("张三", "张全蛋", "王五", "李四");
// 将流元素转换为List集合
List<String> list = stream5.collect(Collectors.toList());
System.out.println(list);
Stream<String> stream6 = Stream.of("张全蛋", "王五", "李四");
// 将流元素转为字符串,并用"and"连接
String str = stream6.collect(Collectors.joining("and"));
System.out.println(str);
Stream<String> stream7 = Stream.of("张全蛋", "王五", "李四");
// 将流元素转为字符串数组,使用String[]::new确保类型安全
String[] arr = stream7.toArray(String[]::new);
// 遍历输出数组中的每个元素
for (String s : arr) {
System.out.println(s);
}
}
}
输出
张三
张全蛋
王五
============================
张全蛋
============================
3
10
18
41
51
66
============================
C1
C2
C3
============================
张全蛋
王五
============================
[张三, 张全蛋, 王五, 李四]
张全蛋and王五and李四
张全蛋
王五
李四
tip:Collectors类提供了很多静态方法,用于将流对象转换为其他形式,如toList()、joining()等。Collectors类中的toList()方法可以将流对象转换为List集合,joining()方法可以将流对象中的元素连接成一个字符串。另外,一个Stream流对象可以连续进行多次中间操作,但是终结操作只能进行一次。
9.4 Parallel Stream(并行流)
前面介绍的创建
Stream流对象的三种方式都是创建的串行流,所谓串行流就是将源数据转换为一个流对象,然后在单线程下执行聚合操作的流。而JDK 8中针对大批量的数据处理还提供了一个并行流,并行流就是将源数据分为多个子流对象进行多线程操作,然后将处理的结果再汇总为一个流对象。

Stream并行流底层会将源数据拆解为多个流对象在多个线程中并行执行,这依赖于JDK 7中新增的fork/join框架,该框架解决了应用程序并行计算的能力,但是单独使用这个框架,必须指定源数据如何进行详细拆分,而JDK 8中的聚合操作,在fork/join框架的基础上进行组合解决了这一麻烦。
使用Stream并行流在一定程度上可以提升程序的执行效率,但是在多线程执行就会出现线程安全这个大问题,所以为了能够在聚合操作中使用Stream并行流,前提是要执行操作的源数据在并行执行过程中不会被修改。
在创建Stream流对象时,除非有特别声明,否则默认创建的都是串行流。JDK 8中提供了两种方式来创建Stream并行流:
- 通过
Collection集合接口的parallelStream()方法直接将集合类型的源数据转变为Stream并行流; - 通过
BaseStream接口的parallel()方法将Stream串行流转变为Stream并行流。另外,在BaseStream接口中还提供了一个isParallel()方法,用于判断当前Stream流对象是否为并行流,方法返回值为boolean类型。
接下来,通过一个案例来学习聚合操作中Stream并行流的创建和基本使用,如例:
例9-4 Demo28.java
import java.util.stream.Stream;
import java.util.List;
import java.util.Arrays;
public class Demo28 {
public static void main(String[] args) {
// 创建一个包含字符串元素的List集合
List<String> list = Arrays.asList("张三", "李斯", "王五");
// 1. 直接使用Collection接口的parallelStream() 方法创建并行流
Stream<String> stream = list.parallelStream();
// 判断当前流是否为并行流,并输出结果
System.out.println(stream.isParallel()); // 输出true,表示是并行流
// 2. 使用BaseStream接口的parallel() 方法将串行流转变为并行流
Stream<String> stream1 = Stream.of("张三", "李斯", "王五");
// 将串行流转换为并行流
Stream<String> parallel = stream1.parallel();
// 判断当前流是否为并行流,并输出结果
System.out.println(parallel.isParallel()); // 输出true,表示是并行流
}
}
输出
true
true
tip:parallelStream()方法和parallel()方法都可以创建并行流,但是parallelStream()方法是通过Collection集合接口创建并行流,而parallel()方法是通过BaseStream接口创建并行流。另外,parallel()方法返回的是一个新的并行流对象,并不会影响原有的串行流对象。