

MySQL 基础(二)
MySQL 基础(二)
每天学习新知识,每天进步一点点。
1. MySQL 函数
MySQL 提供了丰富的内置函数,如字符串函数、数值函数、日期函数、流程函数等。
1.1 字符串函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
| CHAR_LENGTH(str) | 统计字符串 str 的字符个数。 | SELECT CHAR_LENGTH('大海666hello'); | 10 |
| LENGTH(str) | 统计字符串 str 的字节个数。在 UTF-8 编码下,一个汉字三个字节,数字字母一个字节。 | SELECT LENGTH('大海666hello'); | 14 |
| CONCAT(s1, s2, ...) | 合并、拼接字符串。 | SELECT CONCAT('Hello', 'World', 'SYY'); | HelloWorldSYY |
| INSERT(s1, x, len, s2) | 替换字符串,从 s1 的第 x 个字符开始,长度为 len 的子字符串替换为 s2。x 从1开始。如果 x 超过字符串长度或 x 小于1,则返回原 s1。 | SELECT INSERT('HelloWorld-Syy', 2, 3, '1'); | H1oWorld-Syy |
| LOWER(str) | 将字符串 str 中的字母字符全部转换成小写字母。 | SELECT LOWER('SyyHELLO'); | syyhello |
| UPPER(str) | 将字符串 str 中的小写字母转换成大写字母。 | SELECT UPPER('SyyHELLO'); | SYYHELLO |
| LEFT(str, n) | 从字符串 str 的左边开始获取长度为 n 的子字符串。 | SELECT LEFT('HelloWorld', 5); | Hello |
| RIGHT(str, n) | 从字符串 str 的右边开始获取长度为 n 的子字符串。 | SELECT RIGHT('HelloWorld', 5); | World |
| LPAD(s1, len, s2) | 返回字符串 s1,其左边由字符串 s2 填充到 len 字符长度。如果 s1 的长度大于 len,则返回值被缩短至 len 长度。 | SELECT LPAD('Hello', 6, 'World'); | WHello |
| RPAD(s1, len, s2) | 返回字符串 s1,其右边由字符串 s2 填充到 len 字符长度。如果 s1 的长度大于 len,则返回值被缩短至 len 长度。 | SELECT RPAD('Hello', 6, 'World'); | HelloW |
| LTRIM(s) | 删除字符串 s 左侧的空格。 | SELECT LTRIM(' World'); | World |
| RTRIM(s) | 删除字符串 s 右侧的空格。 | SELECT RTRIM('World '); | World |
| TRIM(s) | 删除字符串 s 两侧的空格。 | SELECT TRIM(' Hello World '); | Hello World |
| TRIM(s1 FROM s) | 删除字符串 s 中两端所有的子字符串 s1,包括空格。如果没有指定 s1,则默认删除字符串 s 两侧的空格。 | SELECT TRIM('Hi' FROM 'Hi -SYY- Hi'); | -SYY- |
| REPEAT(s, n) | 重复字符串 s,n 表示重复多少次。 | SELECT REPEAT('Hi~', 3); | Hi |
| SPACE(n) | 返回 n 个空格。 | SELECT CHAR_LENGTH(SPACE(5)), SPACE(5); | 5, ' ' |
| REPLACE(s, s1, s2) | 使用字符串 s2 替换字符串 s 中所有的字符串 s1。 | SELECT REPLACE('SayHiHiHi~', 'Hi', 'Love'); | SayLoveLoveLove~ |
| STRCMP(s1, s2) | 比较字符串 s1 和 s2 的大小,返回 -1、0 或 1。 | SELECT STRCMP('11', '9'); | -1 |
| SUBSTRING(s, n, len) | 获取从字符串 s 的第 n 个字符开始,长度为 len 的子字符串。 | SELECT SUBSTRING('HelloWorld', 2, 5); | elloW |
| MID(s, n, len) | 获取从字符串 s 的第 n 个字符开始,长度为 len 的子字符串。 | SELECT MID('HelloWorld', -3, 2); | ld |
| LOCATE(str1, str) | 返回字符串 str1 在字符串 str 中的首次出现的位置,从1开始。 | SELECT LOCATE('World', 'HelloWorld'); | 6 |
| POSITION(str1 IN str) | 返回字符串 str1 在字符串 str 中的首次出现的位置,从1开始。 | SELECT POSITION('World' IN 'HelloWorld'); | 6 |
| INSTR(str, str1) | 返回子字符串 str1 在字符串 str 中的首次出现的位置,从1开始。 | SELECT INSTR('HelloWorld', 'World'); | 6 |
| FIELD(s, s1, s2, ...) | 返回字符串 s 在列表 s1, s2, ... 中的位置,如果不存在字符串 s 则返回 0,如果字符串 s 是 NULL 也返回 0。 | SELECT FIELD('Say', 'Hi', 'Say', 'Hello', 'Syy', 'Love'); | 2 |
| FIND_IN_SET(s1, s2) | 返回字符串 s1 在字符串列表 s2 中的位置,字符串列表 s2 中字符串用逗号分割。 | SELECT FIND_IN_SET('Love', 'Say,Love'); | 2 |
示例代码:
-- (1)
-- CHAR_LENGTH(str) 统计str的字符个数 -->10
-- LENGTH(str) 统计str的字节个数 在utf8编码下,一个汉字三个字节,数字字母一个字节 -->14
SELECT CHAR_LENGTH( "大海666hello" );
SELECT LENGTH( "大海666hello" );
-- (2) CONCAT(s1,s2,..) 合并、拼接字符串 --> HelloWorldSYY
SELECT CONCAT('Hello','World','SYY');
-- (3) INSERT(s1,x,len,s2) 替换字符串,从s1的x位置开始,长度为len的字符串替换为s2,下标x从1开始,如果x超过字符串长度或x小于1,则返回原s1
-- 这里从2开始,长度为3,替换为1,也就是将`HelloWorld-Syy`中的`ell`替换为`1` --> 'H1oWorld-Syy'
SELECT INSERT('HelloWorld-Syy',2,3,'1');
-- (4)
-- 转换大小写的函数:LOWER(str) 、UPPER(str)
-- LOWER(str) 用于将字符串 str 中的 字母字符全部转换成小写字母 --> syyhello
-- UPPER(str) 用于将 str 中的小写字母转换成大写字母 --> SYYHELLO
SELECT LOWER('SyyHELLO');
SELECT UPPER('SyyHELLO');
-- (5)
-- 获取从左/右开始指定长度的字符串:LEFT(str,n)、RIGHT(str,n)
-- LEFT(str,n) 从str左边开始获取长度为n的字符串 --> Hello
-- RIGHT(str,n) 从str右边开始获取长度为n的字符串 --> World
SELECT LEFT('HelloWorld',5);
SELECT RIGHT('HelloWorld',5);
-- (6) 填充字符串的函数:LPAD(s1,len,s2) 、RPAD(s1,len,s2)
-- LPAD(s1,len,s2) 返回字符串 s1 ,其左边由字符串 s2 填充到 len 字符长度,如果 s1 的长度大于 len ,则返回值被缩短至 len 长度
-- RPAD(s1,len,s2) 返回字符串 s1 ,其右边由字符串 s2 填充到 len 字符长度,如果 s1 的长度大于 len ,则返回值 被缩短至 len 长度
SELECT LPAD('Hello',6,'World'); -- > WHello
SELECT RPAD('Hello',6,'World'); -- > HelloW
-- (7) 删除空格的函数:LTRIM(s) 、RTRIM(s) 、TRIM(s)
-- LTRIM(s) 用于删除字符串 s 左侧的空格
-- RTRIM(s) 用于删除字符串 s 右侧的空格
-- TRIM(s) 用于删除字符串 s 两侧的空格
SELECT LTRIM(' World'); -- World
SELECT RTRIM('World '); -- World
SELECT TRIM(' Hello World '); -- Hello World 注意这里,去除的是两侧的空格,不是全部,所以中间空格会保留
-- (8) 删除指定字符串的函数:TRIM(s1 FROM s) 用于删除字符串 s 中两端所有的子字符串 s1 ,包括空格。 如果没有指定 s1 ,则默认删除字符串 s 两侧的空格
SELECT TRIM('Hi' FROM 'Hi -SYY- Hi'); -- -SYY-
-- (9) 重复生成字符串的函数:REPEAT(s,n) REPEAT(s,n) 用于重复字符串 s ,n 表示重复多少次
SELECT REPEAT('Hi~',3); -- Hi~Hi~Hi~
-- (10) 空格函数:SPACE(n) SPACE(n) 用于返回 n 个空格
SELECT CHAR_LENGTH(SPACE(5)),SPACE(5);
-- (11) 替换函数:REPLACE(s,s1,s2) REPLACE(s,s1,s2) 表示使用字符串 s2 替换字符串 s 中所有的字符串 s1
SELECT REPLACE('SayHiHiHi~','Hi','Love'); -- SayLoveLoveLove~
-- (12) 比较字符串大小的函数:STRCMP(s1,s2)
-- STRCMP(s1,s2) 用于比较字符串 s1 和 s2 的大小,若所有字符串相同则返回 0 ,若第一个字符串大于第二个字符串则返回1,若第一个字符串小于第二个字符串则返回 -1
-- -1,因为比较的是字典顺序,也就是ASCII ,在比较11和9时,1的ASCII值49小于9的ASCII值57,所以字典顺序11小于9,自行多试验,因为基于ASCII ,所以区分大小写
SELECT STRCMP('11','9');
-- (13) 获取子字符串的函数:SUBSTRING(s,n,len) 、MID(s,n,len)
-- SUBSTRING(s,n,len) 用于获取指定位置的子字符串
-- MID(s,n,len) 用于获取指定位置的子字符串
SELECT SUBSTRING('HelloWorld',2,5); -- 从第二位开始,获取5位 elloW
SELECT MID('HelloWorld',-3,2); -- 从倒数第三位开始,获取2位,rl 更推荐SUBSTRING,因为多种数据库都支持,移植性更好
-- (14) 匹配子字符串开始位置的函数:LOCATE(str1,str) 、POSITION(str1 IN str) 、INSTR(str, str1)
-- LOCATE(str1,str) 用于返回字符串 str1 在字符串 str 中的首次出现的位置,从1开始
-- POSITION(str1 IN str) 用于返回字符串 str1 在字符串 str 中的首次出现的位置,从1开始
-- INSTR(str, str1) 用于返回子字符串 str1 在字符串 str 中的首次出现的位置,从1开始
SELECT LOCATE('World','HelloWorld'); -- 6
SELECT POSITION('World' IN 'HelloWorld'); -- 6
SELECT INSTR('HelloWorld','World'); -- 6
-- (15) 反转字符串的函数:REVERSE(s) 用于将字符串 s 反转
SELECT REVERSE("HelloWorld"); -- dlroWolleH
-- (16) 返回指定位置的字符串的函数:ELT(n, s1, s2, s3, .....) ELT(n, s1, s2, s3, .....) 用于返回第 n 个字符串,如果 n 超出范围则返回 NULL
SELECT ELT(5,'Hi','Say','Hello','Syy','Love'); -- Love
-- (17) 返回指定字符串位置的函数:FIELD(s, s1, s2, .....) 用于返回字符串 s 在列表 s1, s2, .... 中 的位置,如果不存在字符串 s 则返回 0 ,如果字符串 s 是 NULL 也返回 0
SELECT FIELD('Say','Hi','Say','Hello','Syy','Love'); -- 2
-- (18) 返回子字符串位置的函数:FIND_IN_SET(s1, s2) 用于返回字符串 s1 在字符串列表 s2 中的位置,字符串列表s2中字符串用,分割
SELECT FIND_IN_SET('Love','Say,Love'); -- 2
1.2 数值函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
| ABS(X) | 返回 X 的绝对值。 | SELECT ABS(-1); | 1 |
| PI() | 返回圆周率的值。 | SELECT PI(); | 3.141593 |
| SQRT(X) | 返回非负数 X 的平方根。 | SELECT SQRT(25); | 5 |
| MOD(X, Y) | 返回 X 除以 Y 的余数,对小数也生效,会精准保留小数。 | SELECT MOD(25.3, 7.5); | 2.8 |
| CEIL(X) | 返回大于等于 X 的最小整数。 | SELECT CEIL(5.3); | 6 |
| FLOOR(X) | 返回小于等于 X 的最大整数。 | SELECT FLOOR(5.3); | 5 |
| RAND(X) | 返回一个0到1之间的随机浮点数,X 作为种子值,用于产生可重复的随机序列。 | SELECT RAND(5); | 0.40613597483014313 |
| ROUND(X, Y) | 对 X 进行四舍五入,Y 用于保留小数位数。 | SELECT ROUND(5.6);SELECT ROUND(5.6572, 3); | 6;5.657 |
| TRUNCATE(X, Y) | 对 X 进行截取,结果保留小数点后 Y 位,只截取,不四舍五入。 | SELECT TRUNCATE(5.65985, 2); | 5.65 |
| SIGN(X) | 返回参数 X 的符号:当 X 为负数时返回 -1,当 X 为正数时返回 1,当 X 为零时返回 0。 | SELECT SIGN(-99); | -1 |
| POWER(X, Y) | 返回 X 的 Y 次方的结果。 | SELECT POWER(5, 3); | 125 |
-- (1) 绝对值函数 ABS(X)
SELECT ABS(-1); -- 1
-- (2) 圆周率 PI()
SELECT PI(); -- 3.141593
-- (3) 平方根 SQRT(x) 返回非负数的平方根
SELECT SQRT(25); -- 5
-- (4) 求余函数 MOD(x,y) 对小数也生效,会精准保留小数
SELECT MOD(25.3,7.5); -- 2.8
-- (5) 求整函数 CEIL(X)、FLOOR(X)
SELECT CEIL(5.3); -- 返回大于等于X的最小整数 6
SELECT FLOOR(5.3); -- 返回小于等于X的最大整数 5
-- (6) 随机数 RAND(X) 返回一个0~1的随机浮点数,x作为种子值,用于产生重复序列
SELECT RAND(5); -- 0.40613597483014313
-- (7) 四舍五入 ROUND(X,Y) 对X进行四舍五入,Y用来保留小数位数
SELECT ROUND(5.6); -- 6
SELECT ROUND(5.6572,3); -- 5.657
-- (8) 截取数值的函数:TRUNCATE(x,y) TRUNCATE(x,y) 用于对 x 进行截取,结果保留小数点后 y 位,只截取,不四舍五入
SELECT TRUNCATE(5.65985,2); -- 5.65
-- (9) 符号函数:SIGN(x) SIGN(x) 用于返回参数 x 的符号,当 x 为负数时返回 -1 ,当 x 为正数时返回 1 , 当 x 为 零时返回 0
SELECT SIGN(-99); -- -1
-- (10) 幂运算函数:POWER(x,y) POW(x,y) 用于返回 x 的 y 次方的结果
SELECT POWER(5,3); -- 125
还有对数函数、三角函数等、不再多说。
1.3 日期和时间函数
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
| CURDATE() | 获取系统当前日期。 | SELECT CURDATE(); | 2025-01-19 |
| CURRENT_DATE() | 获取系统当前日期。 | SELECT CURRENT_DATE(); | 2025-01-19 |
| CURTIME() | 获取系统当前时间。 | SELECT CURTIME(); | 11:58:46 |
| CURRENT_TIME() | 获取系统当前时间。 | SELECT CURRENT_TIME(); | 11:58:46 |
| CURRENT_TIMESTAMP() | 获取系统当前日期和时间。 | SELECT CURRENT_TIMESTAMP(); | 2025-01-19 11:59:49 |
| LOCALTIME() | 获取系统当前日期和时间。 | SELECT LOCALTIME(); | 2025-01-19 11:59:49 |
| NOW() | 获取系统当前日期和时间。 | SELECT NOW(); | 2025-01-19 11:59:49 |
| UNIX_TIMESTAMP() | 获取 UNIX 格式的时间戳(10位)。 | SELECT UNIX_TIMESTAMP(); | 1737259384 |
| FROM_UNIXTIME(unix_date, format) | 将 UNIX 格式的时间戳转换为普通格式的时间。默认格式为 '%Y-%m-%d %H:%i:%s'。 | SELECT FROM_UNIXTIME(1737259384, '%m-%d %H:%i:%s'); | 01-19 12:03:04 |
| UTC_DATE() | 获取当前 UTC (世界标准时间) 日期值。 | SELECT UTC_DATE(); | 2025-01-19 |
| UTC_TIME() | 获取当前 UTC (世界标准时间) 时间值。 | SELECT UTC_TIME(); | 04:05:18 |
| MONTH(date) | 返回 date 对应的月份。 | SELECT MONTH('2025-01-19'); | 1 |
| MONTHNAME(date) | 返回 date 对应的英文全名月份。 | SELECT MONTHNAME('2025-01-19'); | January |
| DAYNAME(date) | 返回 date 对应的工作日的英文名称。 | SELECT DAYNAME('2025-01-19'); | Sunday |
| DAYOFWEEK(date) | 返回 date 对应的一周中的索引,1 表示周日,2 表示周一,......,7 表示周六。 | SELECT DAYOFWEEK('2025-01-19'); | 1 |
| WEEKDAY(date) | 返回日期 date 对应的工作日索引,0 表示周一,1 表示周二,......,6 表示周日。 | SELECT WEEKDAY('2025-01-19'); | 6 |
| WEEK(date) | 计算 date 是一年中的第几周。 | SELECT WEEK('2025-01-19'); | 3 |
| WEEKOFYEAR(date) | 计算日期 date 是一年中的第几周。 | SELECT WEEKOFYEAR('2025-01-19'); | 3 |
| DAYOFYEAR(date) | 返回 date 是一年中的第几天。 | SELECT DAYOFYEAR('2025-01-19'); | 19 |
| DAYOFMONTH(date) | 返回 date 是一个月中的第几天。 | SELECT DAYOFMONTH('2025-01-19'); | 19 |
| YEAR(date) | 返回 date 对应的年份。 | SELECT YEAR('2025-01-19'); | 2025 |
| QUARTER(date) | 返回 date 对应的一年中的季度值。 | SELECT QUARTER('2025-01-19'); | 1 |
| MINUTE(time) | 返回 time 对应的分钟值。 | SELECT MINUTE('12:03:04'); | 3 |
| SECOND(time) | 返回 time 对应的秒数。 | SELECT SECOND('12:03:04'); | 4 |
| EXTRACT(type FROM date) | 获取指定的日期值。type 可以是 YEAR、MONTH、DAY、HOUR、MINUTE、SECOND 等。 | SELECT EXTRACT(YEAR FROM '2025-01-19 12:03:04'); | 2025 |
| TIME_TO_SEC(time) | 将 time 转换为秒钟,公式为 "小时3600 + 分钟60 + 秒"。 | SELECT TIME_TO_SEC('12:03:04'); | 43384 |
| SEC_TO_TIME(time) | 将秒值转换为时间格式。 | SELECT SEC_TO_TIME(43384); | 12:03:04 |
| DATE_ADD(date, INTERVAL expr type) | 对日期进行加运算。expr 是要加的值,type 是时间单位(如 DAY、SECOND、MINUTE 等)。 | SELECT DATE_ADD('2025-01-19 12:03:04', INTERVAL 3 DAY); | 2025-01-22 12:03:04 |
| ADDDATE(date, INTERVAL expr type) | 与 DATE_ADD 功能相同,对日期进行加运算。 | SELECT ADDDATE('2025-01-19 12:03:04', INTERVAL 3 SECOND); | 2025-01-19 12:03:07 |
| DATE_SUB(date, INTERVAL expr type) | 对日期进行减运算。expr 是要减的值,type 是时间单位(如 DAY、SECOND、MINUTE 等)。 | SELECT DATE_SUB('2025-01-19 12:03:04', INTERVAL 2 DAY); | 2025-01-17 12:03:04 |
| SUBTIME(date, date) | 对时间进行减运算。 | SELECT SUBTIME('12:03:04', '4:05:07'); | 07:57:57 |
| SUBDATE(date, INTERVAL expr type) | 与 DATE_SUB 功能相同,对日期进行减运算。 | SELECT SUBDATE('2025-01-19 12:03:04', INTERVAL 2 DAY); | 2025-01-17 12:03:04 |
| DATE_FORMAT(date, format) | 格式化日期,根据 format 指定的格式显示 date 值。 | SELECT DATE_FORMAT('2025-01-19 12:03:04', '%Y-%m-%d'); | 2025-01-19 |
| TIME_FORMAT(time, format) | 格式化时间,根据 format 指定的格式显示 time 值。 | SELECT TIME_FORMAT('12:03:04', '%H:%i'); | 12:03 |
| GET_FORMAT(val_type, format_type) | 返回指定值类型和格式化类型的格式字符串。 | SELECT DATE_FORMAT('2025-01-19', GET_FORMAT(DATE, 'EUR')); | 19.01.2025 |
-- (1) 获取当前日期的函数:CURDATE()、CURRENT_DATE() 用于获取系统当前日期
SELECT CURRENT_DATE(); -- 2025-01-19
-- (2) 获取当前时间的函数:CURTIME()、CURRENT_TIME() 用于获取系统当前时间
SELECT CURRENT_TIME(); -- 11:58:46
-- (3) 获取当前日期和时间的函数:CURRENT_TIMESTAMP() 、LOCALTIME() 、NOW()
SELECT CURRENT_TIMESTAMP(); -- 2025-01-19 11:59:49
-- (4) 获取时间戳的函数:UNIX_TIMESTAMP() 用于获取 UNIX 格式的时间戳, 10位时间戳
SELECT UNIX_TIMESTAMP(); -- 1737259384
-- (5) 转换时间戳的函数:FROM_UNIXTIME(unix_date,format) 用于将 UNIX 格式的时间戳转换为普通格式的时间,默认格式为'%Y-%m-%d %H:%i:%s'
SELECT FROM_UNIXTIME(1737259384,'%m-%d %H:%i:%s'); -- 01-19 12:03:04
-- (6) 获取 UTC 日期的函数:UTC_DATE() 用于获取当前 UTC (世界标准时间) 日期值
SELECT UTC_DATE(); -- 2025-01-19
-- (7) 获取 UTC 时间的函数:UTC_TIME() 用于获取当前 UTC (世界标准时间) 时间值 8小时时差
SELECT UTC_TIME(); -- 04:05:18
-- (8) 获取月份的函数:MONTH(date) 用于返回 date 对应的月份、MONTHNAME(date) 用于返回 date 对应的英文全名月份
SELECT MONTH('2025-01-19'); -- 1
SELECT MONTHNAME('2025-01-19'); -- January
-- (9) 获取星期的函数:DAYNAME(date) 、DAYOFWEEK(date) 、WEEKDAY(date) 、WEEK(date) 、 WEEKOFYEAR(date)
-- DAYNAME(date) 用于返回 date 对应的工作日的英文名称
-- DAYOFWEEK(date) 用于返回 date 对应的一周中的索引,1 表示周日,2 表示周一,...... ,7 表示周六
-- WEEKDAY(date) 用于返回日期对应的工作日索引,0 表示周一,1 表示周二,...... ,6 表示周日
-- WEEK(date) 用于计算 date 是一年中的第几周,一年有 53 周
-- WEEKOFYEAR(date) 用于计算日期 date 是一年中的第几周,一年有 53 周
SELECT DAYNAME('2025-01-19'); -- Sunday
SELECT DAYOFWEEK('2025-01-19'); -- 1
SELECT WEEKDAY('2025-01-19'); -- 6
SELECT WEEK('2025-01-19'); -- 3
SELECT WEEKOFYEAR('2025-01-19'); -- 3
--
-- (10) 获取天数的函数:DAYOFYEAR(date) 、DAYOFMONTH(date)
-- DAYOFYEAR(date) 用于返回 date 是一年中的 第几天,一年有 365 天
-- DAYOFMONTH(date) 用于计算 date 是一个月中的第几天
SELECT DAYOFYEAR('2025-01-19'); -- 19
SELECT DAYOFMONTH('2025-01-19'); -- 19
-- (11) 获取年份的函数:YEAR(date) 返回 date 对应的年份
SELECT YEAR('2025-01-19'); -- 2025
-- (12) 获取季度的函数:QUARTER(date) 返回 date 对应的一年中的季度值
SELECT QUARTER('2025-01-19'); -- 1
-- (13) 获取分钟的函数:MINUTE(time) 返回 time 对应的分钟值
SELECT MINUTE('12:03:04'); -- 3
-- (14) 获取秒钟的函数:SECOND(time) SECOND(time) 返回 time 对应的秒数
SELECT SECOND('12:03:04'); -- 4
-- (15) 获取日期的指定值的函数:EXTRACT(type FROM date) 用于获取指定的日期值,type 可以是 YEAR、MONTH、DAY、HOUR、MINUTE、SECOND 等时间或日期部分。
SELECT EXTRACT(YEAR FROM '2025-01-19 12:03:04'); -- 2025
-- (16) 时间和秒钟转换的函数:TIME_TO_SEC(time) 、SEC_TO_TIME(time)
-- TIME_TO_SEC(time) 用于将 time 转换 为秒钟,公式为 " 小时3600 + 分钟60 + 秒 "
-- SEC_TO_TIME(time) 用于将秒值转换为时间格式
SELECT TIME_TO_SEC('12:03:04'); -- 43384
SELECT SEC_TO_TIME(43384); -- 12:03:04
-- (17) 计算日期和时间的函数:DATE_ADD() 、ADDDATE() 、DATE_SUB() 、SUBDATE() 、ADDTIME() 、 SUBTIME() 、DATEDIFF()
-- DATE_ADD() 用于对日期进行加运算,格式为 DATE_ADD(date, INTERVAL expr type),expr 与 type 的关系
-- DATE_SUB() 用于对日期进行减运算,格式为 DATE_SUB(date, INTERVAL expr type) ,expr 与 type 的关系
-- SUBDATE() 用于对日期进行减运算,格式为 SUBDATE(date, INTERVAL expr type) ,expr 与 type 的关系
-- ADDTIME() 用于对时间进行加运算,格式为 ADDTIME(date, date)
-- SUBTIME() 用于对时间进行减运算,格式为 SUBTIME(date, date)
-- DATEDIFF() 用于计算两个日期之间的间隔天数
SELECT DATE_ADD('2025-01-19 12:03:04',INTERVAL 3 DAY); -- 2025-01-22 12:03:04
SELECT ADDDATE('2025-01-19 12:03:04',INTERVAL 3 SECOND); -- 2025-01-19 12:03:07
SELECT ADDTIME('12:03:04', '4:05:07'); -- 16:08:11
SELECT DATE_SUB('2025-01-19 12:03:04',INTERVAL 2 DAY); -- 2025-01-17 12:03:04
SELECT SUBTIME('12:03:04','4:05:07'); -- 07:57:57
SELECT SUBDATE('2025-01-19 12:03:04',2); -- 2025-01-17 12:03:04
SELECT DATEDIFF('2025-01-10 12:03:04','2025-01-18 07:57:57'); -- -8
-- (18) 将日期和时间格式化的函数:DATE_FORMAT(date, format) 、TIME_FORMAT(time, format) 、 GET_FORMAT(val_type, format_type)
-- DATE_FORMAT(date, format) 用于格式化日期,即根据 format 指定的格式 显示 date 值,format 格式
-- TIME_FORMAT(time, format) 用于格式化时间,即根据 format 指定的格式显示 time 值,format 格式
-- GET_FORMAT() ,我们指定值类型和格式化类型,然后会显示成格式字符串
SELECT DATE_FORMAT('2025-01-19 12:03:04', '%Y-%m-%d'); -- 2025-01-19
SELECT DATE_FORMAT('2025-01-19', '%W, %M %d, %Y'); -- Sunday, January 19, 2025
SELECT TIME_FORMAT('12:03:04','%H:%i'); -- 12:03
SELECT TIME_FORMAT('15:30:45', '%h:%i %p'); -- 03:30 PM
SELECT DATE_FORMAT('2025-01-19', GET_FORMAT(DATE, 'EUR')); -- 19.01.2025
SELECT TIME_FORMAT('15:30:45', GET_FORMAT(TIME, 'USA')); -- 03:30:45 PM
SELECT TIME_FORMAT('15:30:45', GET_FORMAT(TIME, 'JIS')); -- 15:30:45
日期格式说明符:
- %Y:表示四位数的年份(例如:2025)。
- %y:表示两位数的年份(例如:25)。
- %m:表示月份,从 01 到 12。
- %c:表示月份,从 1 到 12(不带前导零)。
- %d:表示一个月中的第几天,从 01 到 31。
- %e:表示一个月中的第几天,从 1 到 31(不带前导零)。
- %M:表示月份的全名(例如:January)。
- %b 或 %h:表示月份的缩写(例如:Jan)。
- %W:表示星期几的全名(例如:Sunday)。
- %a:表示星期几的缩写(例如:Sun)。
时间格式说明符:
- %H:表示 24 小时制的小时,从 00 到 23。
- %k:表示 24 小时制的小时,从 0 到 23(不带前导零)。
- %h:表示 12 小时制的小时,从 01 到 12。
- %I:表示 12 小时制的小时,从 01 到 12。
- %l:表示 12 小时制的小时,从 1 到 12(不带前导零)。
- %i:表示分钟,从 00 到 59。
- %S 或 %s:表示秒,从 00 到 59。
- %p:表示 AM 或 PM。
1.4 流程函数
MySQL 提供了一些流程函数,可以在SQL语句中实现条件筛选,提高语句效率
| 函数 | 说明 | 示例 | 结果 |
|---|---|---|---|
| IF(value, t, f) | 如果 value 条件判断为 true,则返回 t,否则返回 f。 | SELECT IF(10 > 9, 'OK', 'ERROR'); | OK |
| IFNULL(value1, value2) | 如果 value1 不为 NULL,返回 value1,否则返回 value2。 | SELECT IFNULL(NULL, 'Hi'); | Hi |
| CASE [expr] WHEN [val1] THEN [res1] ...[WHEN valN THEN resN].. ELSE [DEFAULT] END | 如果 expr 等于 val1,返回 res1,否则返回默认值。类似 switch case 块。 | SELECT CASE 100 > 99 WHEN TRUE THEN '算对啦' ELSE '算错啦' END; | 算对啦 |
-- (1) IF(value,t,f) 如果value条件判断为true,则返回t,否则返回f
SELECT IF(10>9,'OK','ERROR'); -- OK
-- (2) IFNULL(value1,value2) 如果value1不为null,返回value1,否则返回value2
SELECT IFNULL(null,'Hi'); -- Hi
-- (3) CASE WHEN [val1] THEN [res1] ...[WHEN valN THEN resN].. ELSE [DEFAULT] END 如果val1为true,返回res1,否则返回默认值,类似switch case块
SELECT CASE
WHEN 10 < 9 THEN 'ERROR'
WHEN 10 > 9 THEN 'OK'
ELSE '算不出来'
END; -- OK
-- (4) CASE [expr] WHEN [val1] THEN [res1] ... ELSE [DEFAULT] END 如果expr等于val1返回res1,否则返回默认值,同上
SELECT CASE 100>99
WHEN TRUE THEN '算对啦'
ELSE '算错啦'
END; -- 算对啦
2. 约束
约束是用来限制表中数据的
规则,目的是确保数据的完整性和一致性。
2.1 普通约束
常见的约束有:
| 约束名称 | 描述 | 关键字 |
|---|---|---|
| NOT NULL | 非空约束,确保字段不为 NULL。 | NOT NULL |
| UNIQUE | 唯一约束,确保字段值唯一。 | UNIQUE |
| PRIMARY KEY | 主键约束,唯一标识表中的每一行,不允许重复。 | PRIMARY KEY |
| FOREIGN KEY | 外键约束,用于实现表与表之间的关系。 | FOREIGN KEY |
| CHECK | 检查约束,用于限制字段值的范围。 | CHECK |
| DEFAULT | 默认约束,设置字段的默认值。 | DEFAULT |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
2.2 外键约束
外键约束用于实现表与表之间的关系,通过相同的字段值让两张表的数据建立联系,它是一种
参照完整性约束,用于保证两个表的数据一致性。
使用外键的表叫做子表。被引用的表叫做父表/主表。
2.2.1 创建外键约束
创建外键约束,可以通过创建表时添加 FOREIGN KEY 约束,或者在创建表后使用 ALTER TABLE 语句添加,也可以在图形化工具中添加,方式很多,这里只说明命令语法。
-- 创建表时添加
CREATE TABLE table_name (
字段名 字段类型 [约束条件],
...
[CONSTRAINT] [外键名称] FOREIGN KEY (字段名) REFERENCES 父表名(字段名) [ON DELETE CASCADE | ON UPDATE CASCADE]
);
-- 使用ALTER TABLE添加
ALTER TABLE table_name ADD [CONSTRAINT] [外键名称] FOREIGN KEY (字段名) REFERENCES 父表名(字段名) [ON DELETE CASCADE | ON UPDATE CASCADE];
-- CONSTRAINT 外键名称 :可选,指定外键约束名称。 就是给外键规则起个名字,方便后续删除等管理。
-- FOREIGN KEY (字段名) REFERENCES 父表名(字段名) :指定外键字段和父表的字段的对应关系。
-- ON DELETE CASCADE | ON UPDATE CASCADE :可选,用于指定父表的记录被删除或更新时,子表中相应的记录是否也被删除或更新。
假设此时有一个部门表,部门编号为
dept_no,部门名称为dept_name,有一个员工表,员工编号为emp_no,姓名为emp_name,部门编号为dept_no。
-- 创建部门表
CREATE TABLE dept(
dept_no int PRIMARY KEY AUTO_INCREMENT,
dept_name varchar(50) NOT NULL
);
-- 创建员工表并在创建表时添加外键约束
CREATE TABLE emp(
emp_no int PRIMARY KEY AUTO_INCREMENT,
emp_name varchar(50) NOT NULL,
dept_no int NOT NULL,
CONSTRAINT fk_dept_no FOREIGN KEY (dept_no) REFERENCES dept(dept_no)
);
-- 插入测试数据
INSERT INTO dept (dept_no, dept_name) VALUES
(1, '人事部'),
(2, '财务部'),
(3, '市场部'),
(4, '技术部'),
(5, '运营部');
INSERT INTO emp (emp_name, dept_no) VALUES
('张三', 1),
('李四', 1),
('王五', 4),
('赵六', 3),
('孙七', 2),
('周八', 2),
('吴九', 3),
('郑十', 5),
('陈十一', 4),
('林十二', 1);
-- 创建表后,使用ALTER TABLE 添加外键约束
ALTER TABLE emp ADD CONSTRAINT fk_dept_no FOREIGN KEY(dept_no) REFERENCES dept(dept_no);
2.2.2 外键约束行为
外键约束有三种行为:
CASCADE:级联删除/更新,父表的记录被删除/更新时,子表中相应的记录也被删除/更新。RESTRICT:默认行为,限制删除/更新,父表的记录被删除/更新时,子表中相应的记录不能被删除/更新。NO ACTION:默认行为,限制删除/更新,父表的记录被删除/更新时,子表中相应的记录不被删除/更新。SET NULL:设置 NULL,父表的记录被删除/更新时,子表中相应的记录被设置为 NULL。
2.2.3 删除外键约束
删除外键约束,可以通过 ALTER TABLE 语句删除,也可以在图形化工具中删除,方式很多,这里只说明命令语法。
-- 使用ALTER TABLE删除
ALTER TABLE emp DROP FOREIGN KEY fk_dept_no;
3. 多表查询
在实际生活或者开发中,单一一张表已经无法满足我们实际的开发需要,我们需要更多的数据。但是在一张表中存储过多的数据会影响到服务器的运行效率,所以我们创建多张表并将多张表用某一个字段建立连接,就形成了现在我们需要学习的多表查询。
3.1 多表关系
项目开发中,再进行数据库设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表之间也存在着联系,基本上分为三种:
一对一关系、一对多关系、多对多关系。
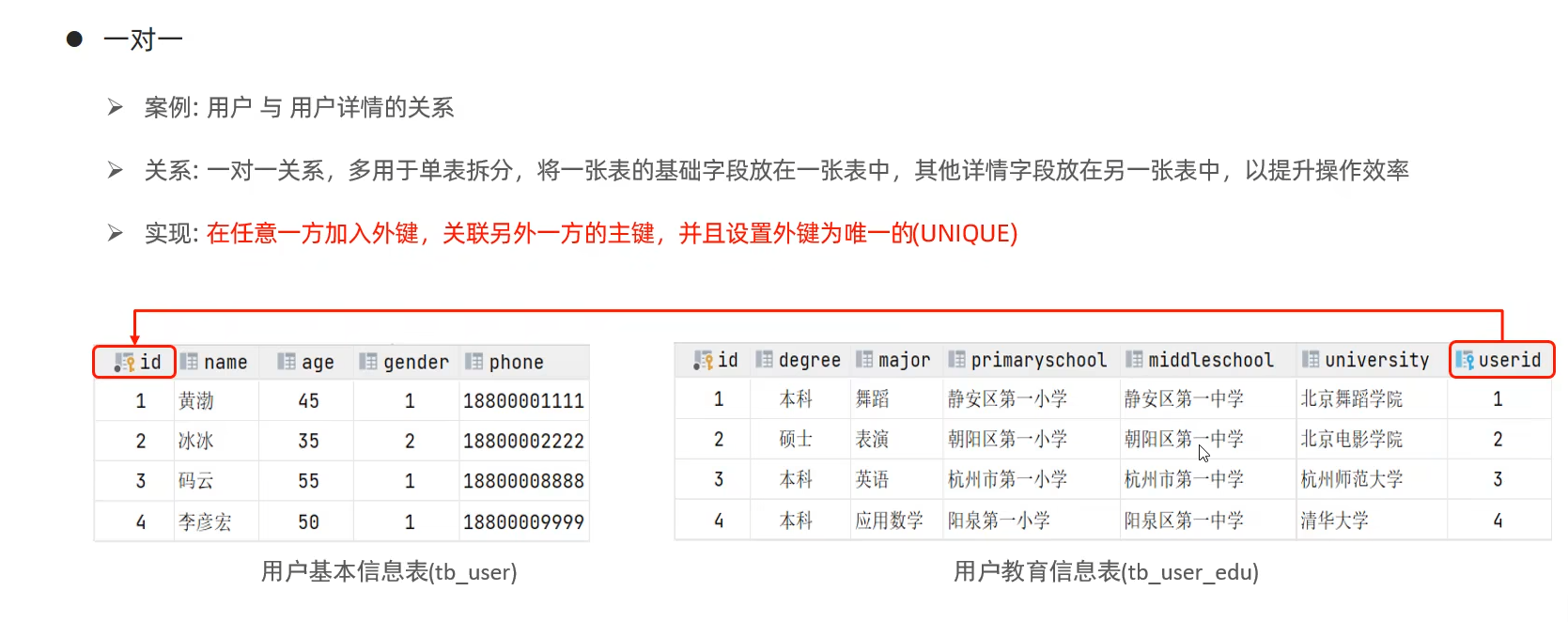

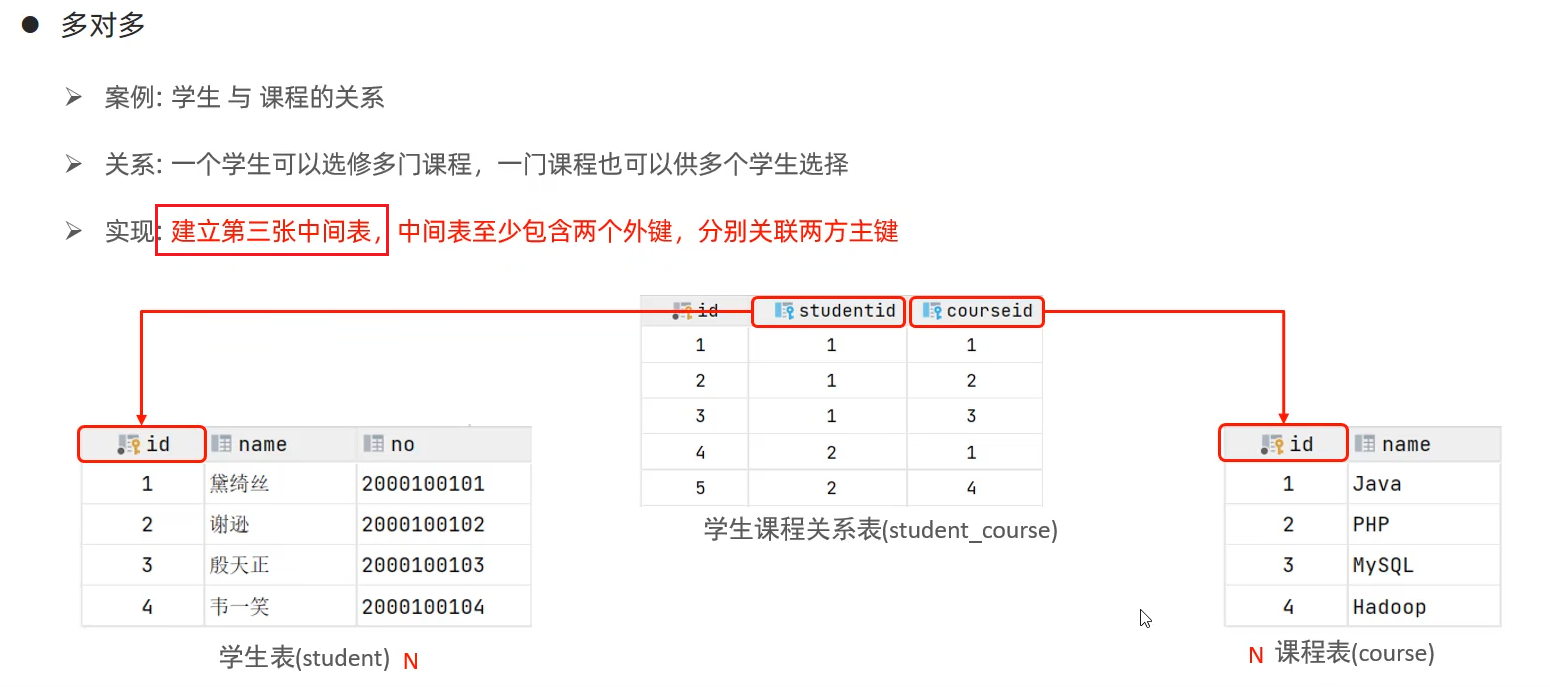
3.2 多表查询分类
- 多表查询分类:
- 连接查询:
- 交叉连接(CROSS JOIN):返回两个表中所有行的笛卡尔积。
- 内连接(INNER JOIN):返回两个表中满足匹配条件的行。
- 外连接(OUTER JOIN):返回两个表中满足匹配条件的行,并在结果中包括没有匹配的行。
- 左外连接(LEFT OUTER JOIN):返回左表中所有行,即使右表没有匹配的行。
- 右外连接(RIGHT OUTER JOIN):返回右表中所有行,即使左表没有匹配的行。
- 全外连接(FULL OUTER JOIN):返回左表和右表中所有行,即使两表没有匹配的行。
- 子查询:
- 标量子查询:返回单个值。
- 列子查询:返回一列值。
- 行子查询:返回一行值。
- 表子查询:返回一个表。
- 联合查询:
- UNION:合并两个或多个 SELECT 语句的结果集,并去除重复的行。
- UNION ALL:合并两个或多个 SELECT 语句的结果集,并保留所有行。
- 连接查询:
3.3 连接查询
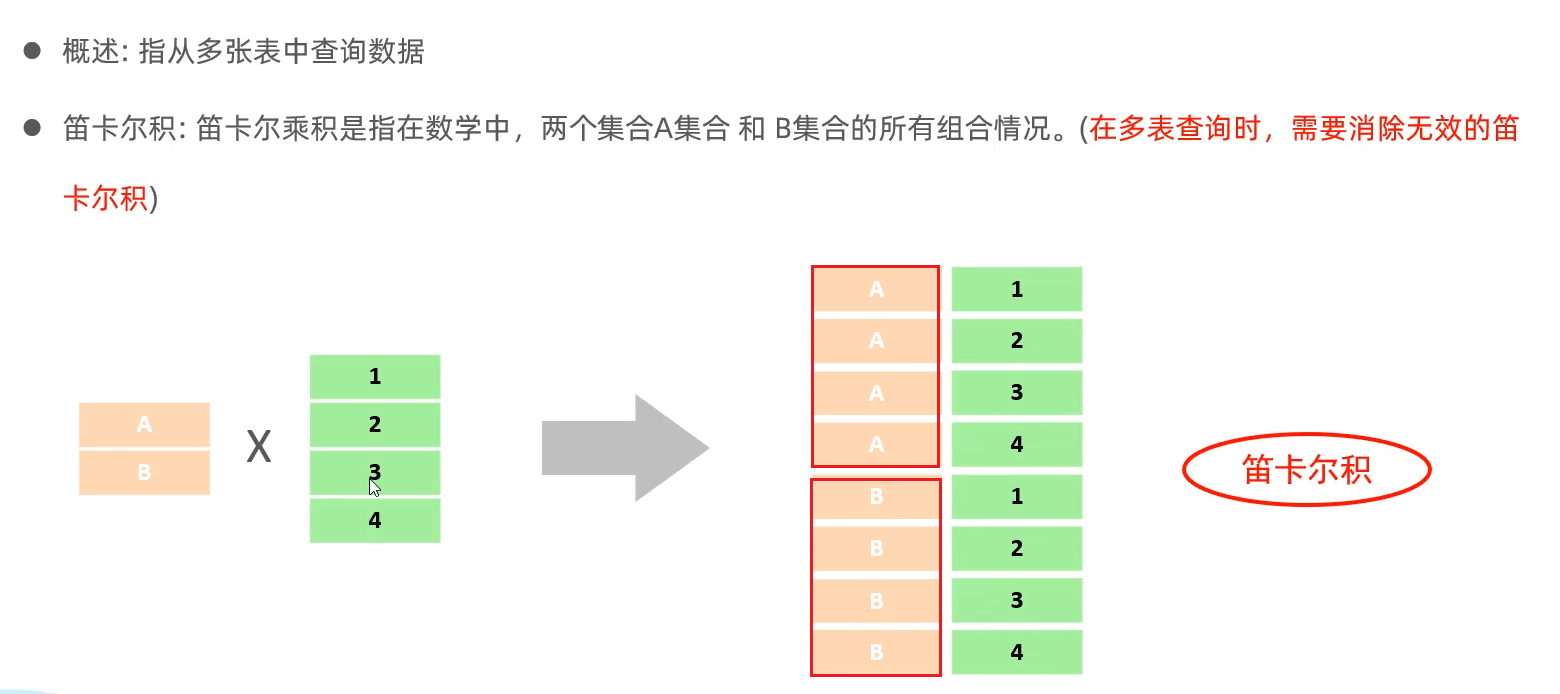
3.1 交叉连接(笛卡尔积)
交叉连接(CROSS JOIN)返回两个表中所有行的笛卡尔积。
SELECT * FROM dept,emp;
查询结果:
dept_no dept_name emp_no emp_name dept_no(1)
1 人事部 1 张三 1
2 财务部 1 张三 1
3 市场部 1 张三 1
4 技术部 1 张三 1
5 运营部 1 张三 1
1 人事部 2 李四 1
2 财务部 2 李四 1
3 市场部 2 李四 1
... // 省略了其他结果,知道是怎么样计算就行了
笛卡尔积将两个表中的所有行组合起来,但是这样的查询结果肯定不是我们想要的,所以为了确保数据的一致性,我们需要对数据进行筛选,只需要在 WHERE 子句中添加条件即可。
-- 保留部门编号一致的数据
SELECT * FROM dept,emp WHERE dept.dept_no = emp.dept_no;
查询结果:
dept_no dept_name emp_no emp_name dept_no(1)
1 人事部 1 张三 1
1 人事部 2 李四 1
1 人事部 10 林十二 1
2 财务部 5 孙七 2
2 财务部 6 周八 2
3 市场部 4 赵六 3
3 市场部 7 吴九 3
4 技术部 3 王五 4
4 技术部 9 陈十一 4
5 运营部 8 郑十 5
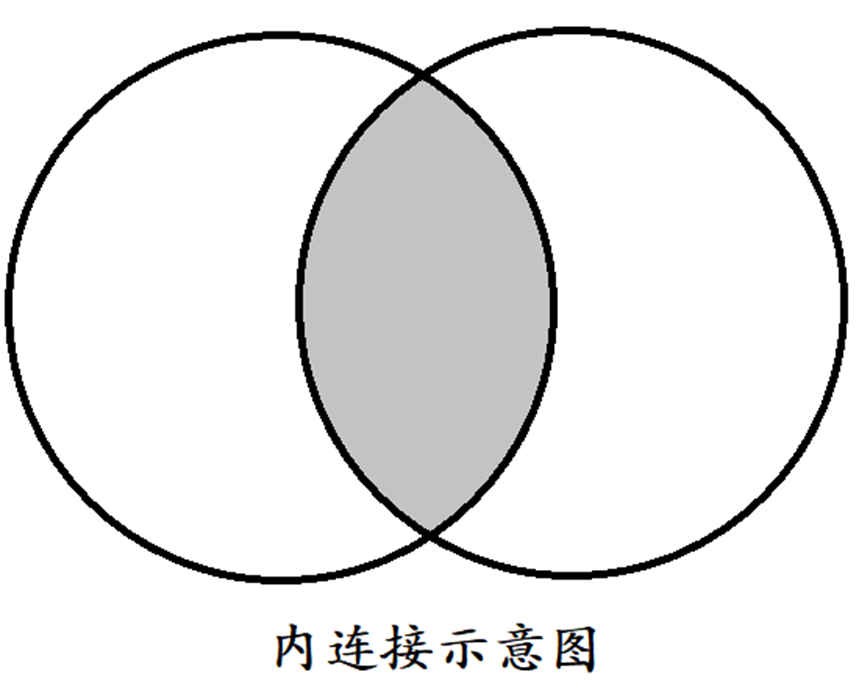
3.2 内连接(INNER JOIN)
内连接(INNER JOIN)返回两个表中满足匹配条件的行。也就相当于查询交集。
语法如下:
-- 隐式内连接 刚刚笛卡尔积消除错误数据增加where子句的写法,其实就是隐式内连接
SELECT 字段列表 FROM 表1,表2 WHERE 条件;
-- 显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;
接下来我们使用内连接查询员工表和部门表:
-- INNER 关键字是可以省略的 这里给表名dept和emp分别取了别名d,e 方便编写条件,将来表名过长不方便写的时候,就可以使用别名(省略了AS)
SELECT * FROM dept d JOIN emp e ON d.dept_no = e.dept_no;
查询结果:
dept_no dept_name emp_no emp_name dept_no(1)
1 人事部 1 张三 1
1 人事部 2 李四 1
1 人事部 10 林十二 1
2 财务部 5 孙七 2
2 财务部 6 周八 2
3 市场部 4 赵六 3
3 市场部 7 吴九 3
4 技术部 3 王五 4
4 技术部 9 陈十一 4
5 运营部 8 郑十 5
3.3 外连接(OUTER JOIN)
外连接(OUTER JOIN)返回两个表中满足匹配条件的行,并在结果中包括没有匹配的行。
3.3.1 左外连接(LEFT OUTER JOIN)
左外连接(LEFT OUTER JOIN)返回左表中所有行,即使右表没有匹配的行。
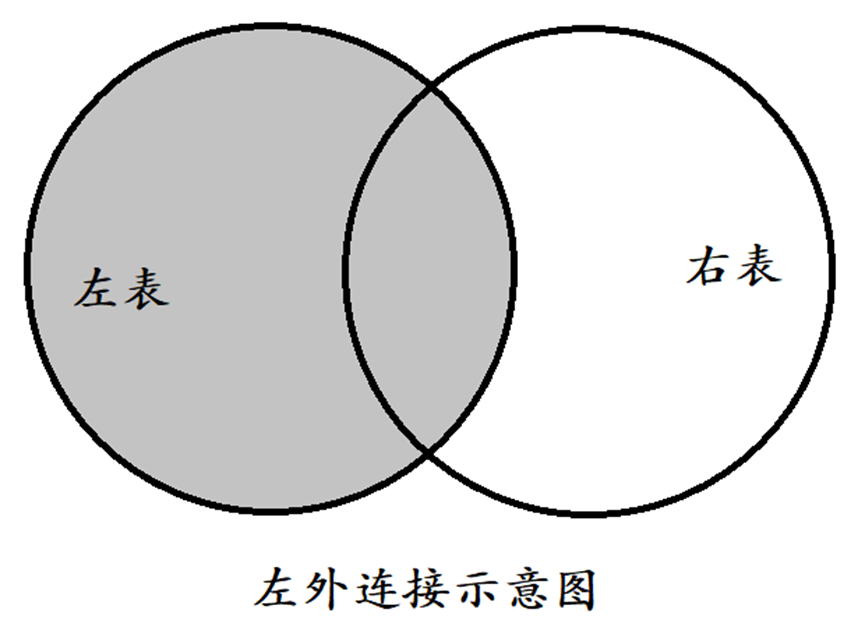
语法如下:
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
-- 左外连接查询员工表和部门表,部门表中没有员工的部门,也会显示出来 可以自行添加测试数据,如果使用上面的测试数据,其实查询是没区别的,我自行添加一条后勤部
SELECT * FROM dept d LEFT JOIN emp e ON d.dept_no = e.dept_no;
查询结果:
dept_no dept_name emp_no emp_name dept_no(1)
1 人事部 1 张三 1
1 人事部 2 李四 1
... // 省略了其他结果
6 后勤部
3.3.2 右外连接(RIGHT OUTER JOIN)
右外连接(RIGHT OUTER JOIN)返回右表中所有行,即使左表没有匹配的行。
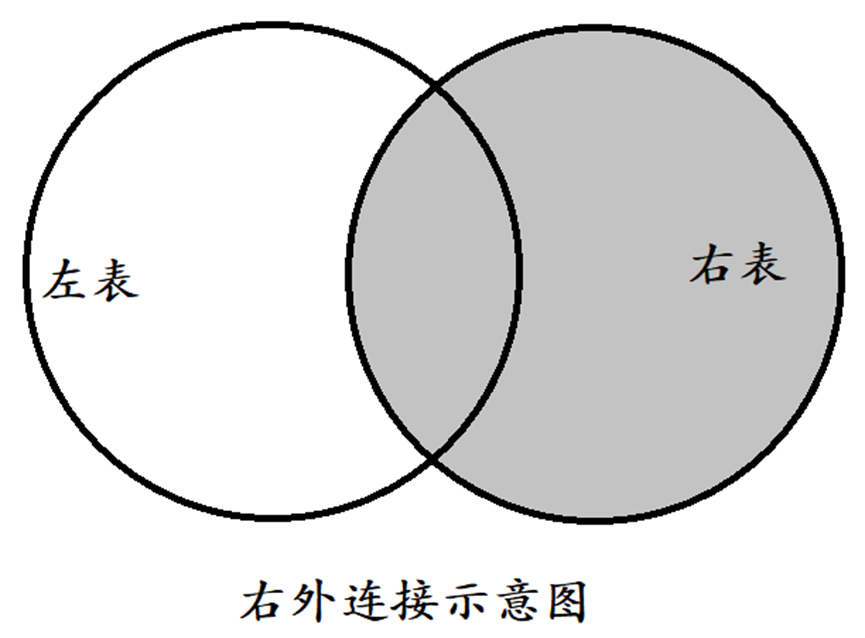
语法如下:
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
-- 右外连接查询员工表和部门表,员工表中没有部门的员工,也会显示出来,这里不再演示,自行添加数据
SELECT * FROM emp e RIGHT JOIN dept d ON e.dept_no = d.dept_no;
3.3 子查询
子查询允许把一个查询 嵌套在另一个查询当中。又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询。
子查询可以包含普通select还可以包括的任何子句,比如:distinct、 group by、order by、limit、join和union等;但是对应的外部查询必须是以下语句之一:select、insert、update、delete
3.3.1 标量子查询
标量子查询(Scalar Subquery)返回单个值。
语法如下:
SELECT 字段 FROM 表名 WHERE 字段 = (SELECT 字段 FROM 表名 WHERE 条件);
(1) 查找人事部门下所有员工信息
(2) 查找一下新来的员工陈十一属于哪个部门
-- (1)
SELECT * FROM emp WHERE dept_no = ( SELECT dept_no FROM dept WHERE dept_name = '人事部' );
-- (2)
SELECT * FROM dept where dept_no = (SELECT dept_no FROM emp WHERE emp_name = '陈十一');
查询结果:
-- (1)
emp_no emp_name dept_no
1 张三 1
2 李四 1
10 林十二 1
-- (2)
dept_no dept_name
4 技术部
3.3.2 列子查询
列子查询(Column Subquery)返回一列/多列值。
常用的操作符有:
- IN:判断某个值是否在子查询的结果集中。
- NOT IN:判断某个值是否不在子查询的结果集中。
- ANY/SOME:判断子查询的结果集中是否有满足条件的行。
- ALL:判断子查询的结果集中是否所有行都满足条件。
(1) 查找人事部和技术部所有员工信息
-- (1)
-- 使用 IN
SELECT * FROM emp WHERE dept_no IN( SELECT dept_no FROM dept WHERE dept_name = '人事部' or dept_name = '技术部');
-- 使用 = ANY
SELECT * FROM emp WHERE dept_no = ANY( SELECT dept_no FROM dept WHERE dept_name = '人事部' or dept_name = '技术部');
-- 使用 = SOME
SELECT * FROM emp WHERE dept_no = SOME( SELECT dept_no FROM dept WHERE dept_name = '人事部' or dept_name = '技术部');
查询结果:
-- 只列出一个,结果是一样的
emp_no emp_name dept_no
1 张三 1
2 李四 1
10 林十二 1
3 王五 4
9 陈十一 4
3.3.3 行子查询
行子查询(Row Subquery)查询返回的结果是一行数据,这一行数据可以包含多个列。行子查询通常用于比较操作。
常用的操作符有:IN、NOT IN、 =、<>
举例:
-- 使用 = 的行子查询 只有当表1中的 (字段1, 字段2) 与子查询返回的 (字段3, 字段4) 完全相等时,相应的行才会被选中
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) = (SELECT 字段3, 字段4 FROM 表2 WHERE 条件);
-- 使用<> 的行子查询 这里的行子查询和使用 = 的行子查询类似,但选择的是 (字段1, 字段2) 与子查询返回的 (字段3, 字段4) 不相等的行。
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) <> (SELECT 字段3, 字段4 FROM 表2 WHERE 条件);
-- 使用 IN 的行子查询 当表1中的 (字段1, 字段2) 与子查询返回的任何一行 (字段3, 字段4) 相等时,该行将被选中。
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) <> (SELECT 字段3, 字段4 FROM 表2 WHERE 条件);
-- 使用 NOT IN 的行子查询 只有当 (字段1, 字段2) 不在子查询返回的行集中时,该行才会被选中。
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) NOT IN (SELECT 字段3, 字段4 FROM 表2 WHERE 条件);
假设现在有两个表table1和table2,对两个表进行行子查询
| table1 | table2 | ||
|---|---|---|---|
| col1 | col2 | col3 | col4 |
| :-: | :-: | :-: | :-: |
| 1 | A | 2 | B |
| 2 | B | 3 | D |
| 3 | C | 4 | D |
-- 1. 使用 = 首先看子查询,返回了字段3和字段4,共四行,然后再table1的四行中查找相等行,首先(2,B)满足,返回一行,只能返回单行数据
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) = (SELECT 字段3, 字段4 FROM 表2);
-- 2. 使用 <> 首先看子查询,返回了字段3和字段4,共四行,然后再table1的四行中查找不相等行,只有(2,B)相等,返回除了这一行其他行,不会返回 col1,col2 为 NULL 的行。
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) <> (SELECT 字段3, 字段4 FROM 表2);
-- 3. 使用 IN 首先看子查询,返回了字段3和字段4,共四行,然后再table1的四行中查找相等任意一行,只有(2,B)满足,返回一行,可返回多行数据
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) IN (SELECT 字段3, 字段4 FROM 表2);
-- 4. 使用 = 首先看子查询,返回了字段3和字段4,共四行,然后再table1的四行中查找不相等行,只有(2,B)相等,返回除了这一行其他行,有NULL值可能影响结果
SELECT 字段1, 字段2
FROM 表1
WHERE (字段1, 字段2) NOT IN (SELECT 字段3, 字段4 FROM 表2);
3.3.4 表子查询
表子查询(Table Subquery)返回多行多列,也就是一个表。
常用操作符为:IN
举例:
查询与“张三”,“李四”的工作地点和薪资相同的员工信息(这里表创建时没有这些字段,方便演示,所以只举例,不演示运行结果)
SELECT * FROM emp WHERE (workAddress,salary) in (SELECT workAddress,salary FROM emp WHERE dept_name = '张三' or dept_name = '李四');
这里子查询返回了张三和李四的工作地点和薪资,也就是两行两列,就是表子查询。
3.4 联合查询
联合查询(Union)用于合并两个或多个 SELECT 语句的结果集。
UNION 和 UNION ALL (合并、并集)
UNION 合并两个或多个 SELECT 语句的结果集,并去除重复的行。
UNION ALL 合并两个或多个 SELECT 语句的结果集,并保留所有行。
语法如下:
SELECT 字段 FROM 表名1 UNION SELECT 字段 FROM 表名2;
SELECT 字段 FROM 表名1 UNION ALL SELECT 字段 FROM 表名2;
| table1 | table2 | ||
|---|---|---|---|
| col1 | col2 | col3 | col4 |
| :-: | :-: | :-: | :-: |
| 1 | A | 2 | B |
| 2 | B | 3 | D |
| 3 | C | 4 | D |
还是使用这个表格进行举例:
- 使用UNION后,会
合并后进行去重,所以结果为(1,A),(2,B),(3,C),(3,D),(4,D) - 使用UNION ALL后,会
合并后保留所有行,所以结果为(1,A),(2,B),(3,C),(2,B),(3,D),(4,D)